
大语言模型基础:理论与实践
从0到1构建自己的mini-ChatGPT
完整PyTorch代码实操细讲,经典论文复现
NLP技术关键技术发展脉络精讲,注意力机制和Transformer架构全面剖析
 讲师:黄佳
讲师:黄佳

对课程有疑问? 点击视频立即观看课程介绍!
 您已经是《大语言模型基础:理论与实践》-学员,是否购买最新一期?
您已经是《大语言模型基础:理论与实践》-学员,是否购买最新一期?
- 本课程包括:
- 3个月群内答疑,讲师助教及时解答
- 课程有效期为1年,建议合理规划学习
- 课程配有作业练习,助教一对一批改
- 班主任带班,严格督学,告别拖延
- 根据学习情况颁发结业证书、优秀学员证书
黄佳
新加坡科技研究局人工智能高级研究员,主攻方向为NLP大模型的研发与应用、持续学习、AI in FinTech、AI in Spectrometry Data。曾著有《零基础学机器学习》、《数据分析咖哥十话》等多部畅销书籍,深耕数据科学领域多年,积累了丰富的科研项目和政府、银行、能源、医疗等领域AI项目落地实战经验。
随着ChatGPT的爆火,大语言模型(LLM)得到了空前的关注,各行各业的从业者开始应用ChatGPT提升日常工作效率。那么该如何构建属于自己的mini-ChatGPT?又需要掌握哪些核心技术呐?本课程会给你答案!课程会从语言模型的概念以及经典方案开始讲起,逐渐演进到ChatGPT中使用的基于Transformer的语言模型以及注意力(Attention)机制,并从思想层面透彻地解释Attention机制为什么有效,最后带着大家实现自己的mini-ChatGPT。在讲解原理的同时,课程非常注重代码实践,算法的代码实现穿插于每个算法理论之中。上述的课程设计,极大降低了课程学习门槛,相信每一位学习过Python以及概率论、线性代数的同学,都能够收获颇丰。
课程目标
自主开发属于自己的ChatGPT
目标 O1
掌握语言模型的经典与主流算法,及其发展脉络
目标 O2
深刻理解ChatGPT的若干核心技术
目标 O3
动手实现mini版本的ChatGPT
课程脉络
-
01 基础概念
1
基础概念:ChatGPT属于大语言模型的一类,那么首先课程会通俗地讲解“什么是语言模型,什么是大语言模型”,在讲解语言模型时,会引出词向量、词嵌入等NLP领域几个最常用的概念,以及经典方法Word2Vec。
-
02 核心算法
2
核心算法:过去的十余年,语言模型的算法层出不穷,课程案例算法的演变脉络,精选了早期的N-gram以及基于浅层神经网络的NPLM进行详细讲解,并逐步过渡到基于深层网络的语言模型(生成式语言模型GPT)。GPT模型的深层网络不再采用CNN, RNN或者LSTM等结构,而是采用表达能力更强的Transformer,因此在讲解GPT模型时会细致讲解“Transformer的思想是什么,其核心组件有哪些,为什么其表达能力更强”。
-
03 综合实践
3
综合实践:每个核心算法的原理讲解,都会配套其代码实现,便于同学们学以致用。同时,课程也会带大家实现一个mini版本的ChatGPT:考虑到同学们算力资源有限,课程提供一个小型的数据集,将详细讲解如何准备数据、搭建模型架构、进行训练和评估,进而在该小型数据集上训练GPT模型。
课程大纲
-
第1章:从图灵测试到ChatGPT-NLP技术发展简史
本课梳理了NLP技术的发展进化过程的四阶段,分别是:起源、基于规则的方法、基于统计的语言模型、大数据驱动的深度学习模型。同时介绍了NLP演进过程中的各种关键技术,着重介绍了语言模型的原理。
-
第2章:语言模型的早期形式-N-gram实战
本课进一步诠释“语言模型的内涵是一种用于计算和预测自然语言序列概率分布的模型”,并通过N-gram模型来解释语言模型如何通过分析语言数据来建立数学模型,推断和预测下一个单词,并通过代码实践实现一个N-gram语言模型。
-
第3章:词的向量表示是如何习得的-Word2Vec实战
本课重点介绍词向量表示的概念和学习方法,以Word2Vec的Skip-Gram和CBOW算法为例,详细讲解其原理和实现。通过代码实践,学生将了解如何使用Word2Vec模型将词汇表达为词向量,以捕捉词汇之间的语义关系。
-
第4章:BERT,GPT等大模型的起点-神经概率语言模型NPLM
本课将介绍神经概率语言模型(NPLM)的基本原理和实现,学生将了解NPLM如何利用神经网络来学习语言表示,并为后续的各种深度学习语言模型的学习奠定基础。实践部分……
项目实践
-
项目一:N-Gram构建
自然语言入门——统计式语言模型的构建,最早的语言模型通过统计语料库的词频,来计算下一个词生成的概率,在一个小型的语料库上,构建N-Gram模型。
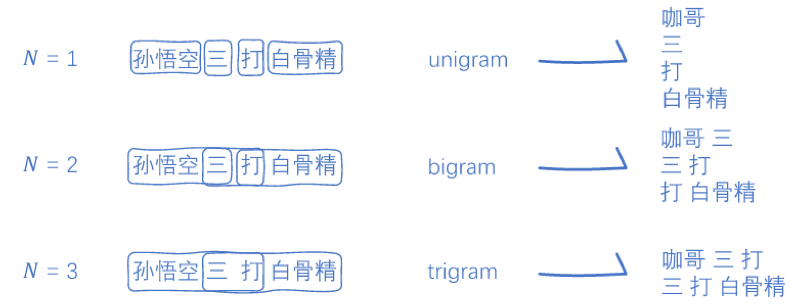
-
项目二:Word2Vec构建
弥补独热编码来表示词的缺点,通过简单的神经网络构建自己的词特征向量从而实现词向量在特征空间上拥有更近的语义,提高计算效率。搭建自己的CBOW模型以及Skip - gram模型。
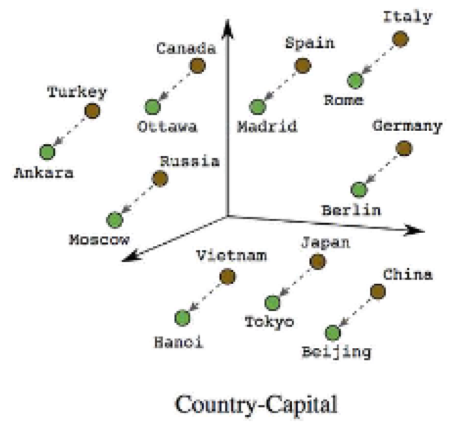
-
项目三:NPLM(Neural Probabilistic Language Model)构建
大语言模型的起点——神经概率语言模型,一种动态变化并且能根据上下文不断自适应改变的词向量表示的语言模型,通过学习文本数据的概率分布,能够预测下一个单词或字符的概率,从而生成连贯的语句或段落,在小型语料库上搭建首个生成式语言模型。
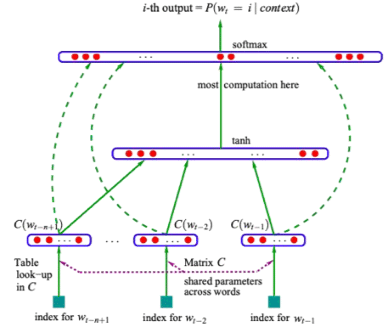
-
项目四:Seq2Seq架构
Transformer基础架构——Seq2Seq架构, 在一个8万个中英翻译的真实的平行语料库中, 利用不同的时序模型以及框架完成一个机器翻译的任务,并且利用BLUE指标进行评价。
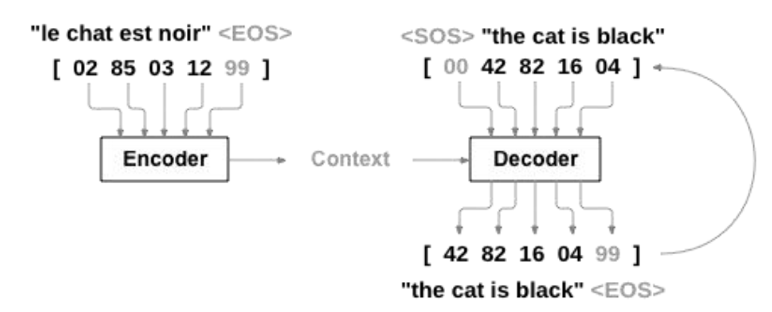
-
项目五:注意力机制
Transformer核心机制——注意力,从点积注意力入手,了解注意力以及自注意力中的QKV的区别,逐步实现多头缩放点积自注意力机制,加入注意力掩码,从而对前一节的Seq2Seq架构进行重构,实现多头自注意力的编解码器结构。
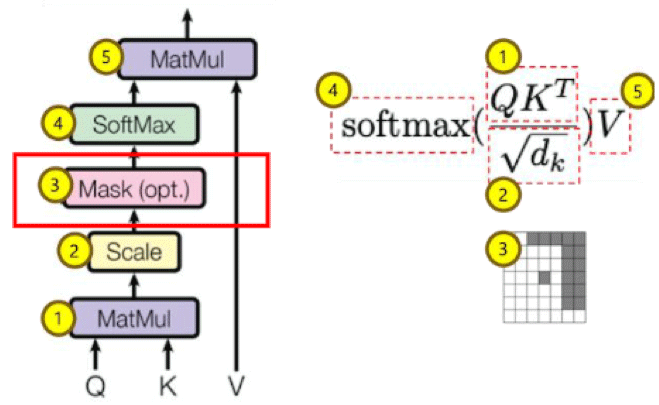
-
项目六:Transformer架构
大语言模型基石——Transformer, 从0到1逐个组件拆解Transformer架构,通过将Transformer结构拆解成多头自注意力,逐位置前馈网络,正弦位置编码表,填充位置掩码,编码器层,编码器,后续位置掩码,解码器层以及解码器,最终搭建自实现的Transformer,从而完成机器翻译任务。
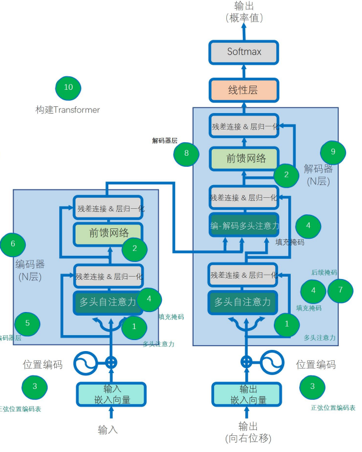
-
项目七:WikiGPT
了解GPT(decoder-only)的基础原理,通过将GPT拆解成多头自注意力,逐位置前馈网络,正弦位置编码表,填充位置掩码,后续位置掩码,解码器层及解码器结构,从而实现一个小型的GPT结构并结合WikiText数据集训练自己的WikiGPT模型。
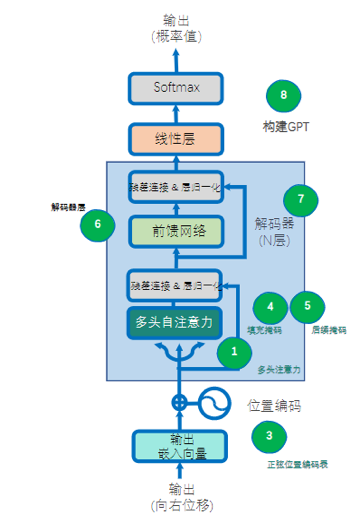
-
项目八:miniChatGPT
实战1:结合上一节的WikiGPT,加入Movie Dialog语料库对WikiGPT进行微调,使得其获得对话的能力从而得到minichatGPT 。 实战2:利用DeepSpeed框架训练一个开源的1.3Bchatgpt模型,深入了解GPT3 - GPT3.5 的训练机制改变,了解SFT(supervised fine tuning), 奖励模型微调(RW)以及 PPO(Proximal Policy Optimization)算法以及RLHF(Reinforcement Learning Human Feedback)。
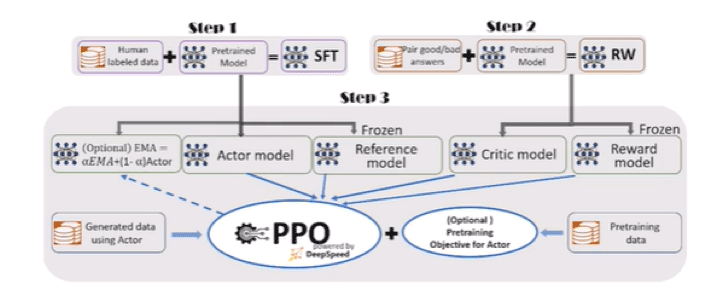
-
项目九:Prompt Engineering实战
通过调用一些OpenAI的API从而熟悉Prompt Engineering的过程,熟悉掌握few-shot以及COT的技巧,完成以下三个任务。
1.设定不同的角色带入回答
2.利用提示工程技巧减少模型的幻觉出现的频次
3.针对固定场景,让AI生成客服反馈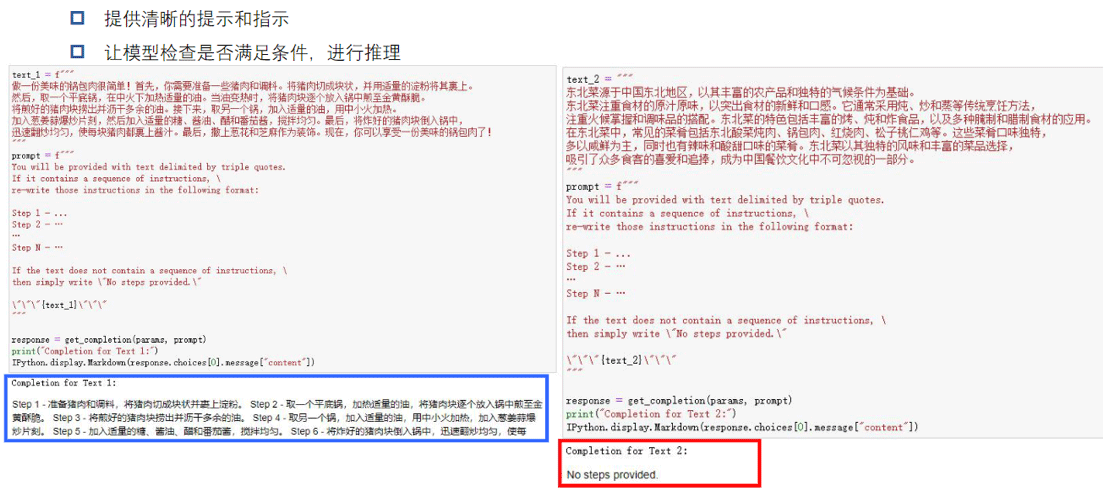
学习收获
- 1你将获得现代NLP技术的关键内核和完整脉络(摒弃一切已经不需要过多了解的过时东西)
- 2你将掌握NLP领域编程基本功和PyTorch主要内容
- 3你将搭建起一个属于你自己的简版ChatGPT(生成式语言模型)
- 4你将掌握注意力机制和Transformer架构的核心思想以及代码实现
- 课程适合谁学习
- NLP领域学生、研究人员
- 任何对ChatGPT和生成式模型有兴趣的人
- 基础不深,但是想入门AI的初学者
- 课程所需的基础知识
- Python基本知识
- 概率论、线性代数等数学基础知识
- 最好有PyTorch基础知识
全方位的学习服务
个性化增值服务,学习有保障更高效
-
 作业批改
作业批改
作业批改 助教1V1批改作业,定期针对作业中的“通病”进行点评
-
 结业证书
结业证书
结业证书 本课程将根据作业完成情况评选结业学员及优秀学员,颁发证书
-
 实时答疑
实时答疑
实时答疑 讲师微信群答疑,及时解决大家遇到的问题
-
 班班督学
班班督学
班班督学 班主任全程带班,不定时“关照”未交作业的同学,克服拖延
- 1:开课仪式
- 2:0819直播答疑回放
-
第1章: 从图灵测试到ChatGPT-NLP技术发展简史 4节课程·1小时2分钟
本章节梳理了NLP技术的发展进化过程的四阶段,分别是:起源、基于规则的方法、基于统计的语言模型、大数据驱动的深度学习模型。同时介绍了NLP演进过程中的各种关键技术,着重介绍了语言模型的原理。
- 3:【课件】从图灵测试到ChatGPT-NLP简史-3.1.pdf
-
第1节: 语言是什么?
- 4:【视频】语言模型的引入
-
第2节: 语言模型的进化
- 5:【视频】语言模型的进化
-
第3节: 预训练语言模型:BERT和GPT
- 6:【视频】预训练语言模型
-
第4节: 大模型的使用模式
- 7:【视频】大模型的使用模式:Pretrain+fine-tuning与Prompt-Instruct
-
第2章: 语言模型的早期形式-N-gram实战 4节课程·1次作业·46分钟
本章节进一步诠释“语言模型的内涵是一种用于计算和预测自然语言序列概率分布的模型”,并通过N-gram模型来解释语言模型如何通过分析语言数据来建立数学模型,推断和预测下一个单词,并通过代码实践实现一个N-gram语言模型。
- 8:【课件】最简单的语言模型N-gram
-
第1节: 再谈什么是语言模型
- 9: 【视频】再谈什么是语言模型
-
第2节: N-gram:最早最简单的语言模型
- 10: 【视频】N-gram
-
第3节: NLP中的分词
- 11:【视频】英文分词中的子词
-
第4节: 实践:创建一个bigram字符预测模型
- 12-1:【代码】02_NGram
- 12-2:【视频】创建一个bigram字符预测模型
- 12-3:【作业】创建一个Bigram字符预测模型
-
第3章: 词的向量表示是如何习得的-Word2Vec实战 9节课程·1次作业·1小时8分钟
本章节重点介绍词向量表示的概念和学习方法,以Word2Vec的Skip-Gram和CBOW算法为例,详细讲解其原理和实现。通过代码实践,学生将了解如何使用Word2Vec模型将词汇表达为词向量,以捕捉词汇之间的语义关系。
- 13:【课件】Lecture3 词的向量表示Word2Vec
-
第1节: 计算机如何表示词?
- 14:【视频】计算机如何表示词
-
第2节: One-Hot编码
- 15: 【视频】One-Hot编码
-
第3节: 词的分布式表示
- 16:【视频】 词的分布式表示
-
第4节: 词向量的定义
- 17:【视频】词向量的定义
-
第5节: 语言模型与词向量之间的关系
- 18:【视频】语言模型为什么需要词向量
-
第6节: Word2Vec:一种高效的词向量学习方法
- 19: 【视频】Word2Vec的思想
-
第7节: 实践:创建一个Skip-Gram词向量模型
- 20:【视频】Skip-Gram词向量模型实践
-
第8节: Word2Vec总结:训练过程及其局限
- 21:【视频】Word2Vec总结:训练过程及其局限
-
第9节: 【作业】Word2Vec
- 22-1:【代码】03_Word2Vec
- 22-2:【视频】作业安排
- 22-3:【作业】第三章
-
第4章: BERT,GPT等大模型的起点-神经概率语言模型NPLM 4节课程·1次作业·56分钟
本章节将介绍神经概率语言模型(NPLM)的基本原理和实现,学生将了解NPLM如何利用神经网络来学习语言表示,并为后续的各种深度学习语言模型的学习奠定基础。实践部分,将带领学生一起搭建一个以RNN网络为内部层结构的神经概率语言模型,预测句子中的下一个单词。
- 23:【课件】神经概率语言模型NPLM
-
第1节: 词向量的局限与神经网络的引入
- 24:【视频】神经概率语言模型的引入
-
第2节: 神经概率语言模型:NPLM
- 25: 【视频】NPLM思想与结构
-
第3节: 实践:创建一个NPLM模型
- 26:【视频】NPLM模型实践
-
第4节: NPLM模型的增强与改进
- 27-1:【代码】04_NPLM
- 27-2:【视频】NPLM模型的增强与改进
- 27-3:【作业】 NPLM模型的增强与改进
-
第5章: Transformer的基础架构-序列到序列-Seq2Seq 5节课程·1次作业·53分钟
本章节介绍一种重要的NLP模型架构——序列到序列(Seq2Seq),详细讲解其编码器-解码器结构的基本原理与应用场景。通过学习本课,学生将了解为何Seq2Seq在处理序列到序列的任务时具有优势,以及如何利用Seq2Seq模型处理各种序列到序列任务,这将为后续Transformer模型的学习打下坚实基础。代码实践部分,将带领学生一起搭建一个以RNN网络为内部层结构的Seq2Seq模型,完成简单的文本翻译任务。
- 28:【课件】Transformer的基本架构-序列到序列-Seq2Seq
-
第1节: 通信原理:编码-解码
- 29:【视频】Seq2Seq的思想由来
-
第2节: Seq2Seq架构
- 30:【视频】Seq2Seq架构详解
-
第3节: Seq2Seq架构适合处理哪类NLP问题?
- 31:【视频】Seq2Seq模型实现机器翻译任务
-
第4节: Seq2Seq的历史地位与局限
- 32:【视频】Seq2Seq的局限
-
第5节: 实践:创建一个Seq2Seq模型
- 33-1:【代码】05_Seq2Seq Code
- 33-2:【视频】作业说明
- 33-3:【作业】创建一个Seq2Seq模型
-
第6章: Transformer的核心机制-详解注意力Attention 4节课程·1次作业·1小时3分钟
本章节重点介绍Transformer模型的核心机制——注意力(Attention)机制。我们将详细解析缩放点积注意力、编码器-解码器注意力、自注意力(Self-Attention)、多头注意力(Multi-Head Attention)的工作原理和代码实现。通过本课的学习,学生将了解注意力机制如何帮助Seq2Seq模型捕捉长距离依赖和实现并行计算。
- 34-1:【课件】Transformer的核心机制-注意力Attention
- 34-2:【代码】Attention.zip
-
第1节: 注意力机制如何解决了Seq2Seq的局限
- 35:Seq2Seq的局限以及Attention如何解决这种局限
-
第2节: 从简单到复杂,逐步拆解注意力机制
- 36-1:【视频】点积注意力思想
- 36-2:【视频】缩放点积注意力
- 36-3:【视频】编码器-解码器注意力
- 36-4:【视频】自注意力与多头注意力
-
第3节: 注意力中的掩码
- 37:【视频】注意力中的掩码
-
第4节: 注意力机制总结
- 38-1:【代码】06_Attention
- 38-2:【视频】总结
- 38-3:【作业】注意力机制
- 38-4:【作业思路】Attention注意力机制
-
第7章: ChatGPT的内核-Transformer详解 4节课程·1次作业·1小时38分钟
本章节深入剖析Transformer模型的架构和原理及实现细节。通过本课的学习,学生将完全学透Transformer模型的关键技术和底层逻辑。实践部分,将带领学生一起搭建一个完整的Transformer模型,并完成一个文本翻译任务。
- 39:【课件】Transformer的架构拆解和代码实现
-
第1节: 基于注意力机制的Seq2Seq有何弊端
- 40:【视频】Transformer引入
-
第2节: Transformer架构拆解
- 41-1:【视频】Transformer架构概览
- 41-2:【视频】组件:缩放点积注意力与多头注意力
- 41-3:【视频】组件:逐位置前向传播与正弦位置编码
- 41-4:【视频】组件:填充位置掩码
- 42:【视频】组件:编码器与解码器层
-
第3节: 实践:基于Transformer的机器翻译
- 43:【视频】基于Transformer的机器翻译
-
第4节: 作业:利用Transformer完成机器翻译任务
- 44-1:【代码】Transformer Code
- 44-2:【视频】作业
- 44-3:【作业】利用Transformer完成机器翻译任务
- 44-4:【作业思路】Transformer
-
第8章: 训练你的简版生成式语言模型-GPT 5节课程·1次作业·1小时19分钟
本章节带领学生训练一个简化版的生成式预训练模型——GPT。我们将详细讲解如何准备数据、搭建模型架构、进行训练和评估,实现文本生成任务。通过本课的学习,学生将了解到GPT模型的实际操作流程,为自己的项目奠定基础。
- 45:【课件】L8 GPT:生成式预训练Transformer
-
第1节: 为什么GPT只需要Decoder
- 46:【视频】为什么GPT只需要Decoder
-
第2节: 基础模型
- 47:【视频】基础模型
-
第3节: GPT架构:逐组件拆解
- 48:【视频】GPT模型架构
-
第4节: 工程实践:用WikiText训练Wiki-GPT
- 49-1:【实践】训练Wiki-GPT
- 49-2:【视频】程序架构梳理
-
第5节: 作业:训练你的ChatGPT
- 50-1:【代码】WikiGPT
- 50-2:【视频】作业
- 50-3:【作业】WikiGPT
- 50-4:【作业思路】GPT
-
第9章: 从GPT到ChatGPT-基于人类反馈的强化学习 5节课程·1次作业·2小时0分钟
本章节使用对话数据集对上一章中训练的GPT模型进行优化,以实现具备聊天对话功能的mini-ChatGPT模型。同时还将初步探讨如何通过基于人类反馈的强化学习方法来优化ChatGPT模型,实现更高质量的生成效果。
- 51:【课件】基于人类反馈的强化学习RLHF
-
第1节: Transformer大模型家族谱系
- 52:【视频】Transformer大模型家族谱系
-
第2节: ChatGPT训练方法
- 53:【视频】ChatGPT训练方法
-
第3节: ChatGPT整体训练流程
- 54-1:【视频】ChatGPT整体训练流程
- 54-2:【视频】miniChatGPT
-
第4节: DeepSpeed Chat介绍
- 55-1:【视频】DeepSpeed Chat介绍
- 55-2:【视频】Deepspeed01
- 55-3:【视频】Deepspeed02
-
第5节: 作业
- 56-1:【代码】09_ChatGPT
- 56-2:【视频】作业安排
- 56-3:【作业】miniChatGPT
- 56-4:【作业思路】GPT
-
第10章: 站在巨人的肩上- Prompt Engineering(提示工程) 4节课程·1次作业·57分钟
本章节通过GPT-4(3.5)API实战来介绍Prompt Engineering(提示工程)的原则、技巧,以及注意事项。我们会讲解OpenAI API的使用方法,通过实际案例演示,让学生将了解如何在自己的项目中快速实现高效的自然语言处理功能。
- 57:【课件】Lecture10 GPT-4 API - Prompt Engineering
-
第1节: 章节介绍
- 58:【视频】章节介绍
-
第2节: AGI的星星之火
- 59:【视频】AGI的星星之火
-
第3节: 提示工程技巧
- 60:【视频】提示工程技巧
-
第4节: 提示工程实践
- 61-1:【代码】10_GPT4-API
- 61-2:【视频】提示工程实践
- 61-3:【作业】提示工程实践
- 61-4:【视频】L10 示范
- 61-5:【作业思路】GPT_API

课程讨论区
已累计讨论26495个问题
课程配备专属讨论区,不仅有讲师、助教全程答疑,更能与同学们交流讨论,在思维碰撞中加深理解
在课程中随想随问,同学们的问题也可能启发到你

在课程讨论区,和684位同学一起探讨更多问题···
作业批改
已累计批改4951份作业
助教一对一批改作业,定期针对作业中的问题进行评讲
结业证书
课程根据作业完成情况评选结业学员及优秀学员,颁发证书
优秀学员更能获得额外购课优惠

班班督学
班班、助教、讲师全程带班,日常答疑解惑
FAQ
1、课程可以试听吗?
可以,您可以联系客服领取试听内容,根据试听的效果决定是否报名。
2、报名课程后,如果不满意,可以退款吗?
我们承诺: 报名后7天内且学习进度停留在第一章节的内容可以无条件全额退款,若您的学习进度超过第一章或报名时间超过7天将不再支持退款哦。课好不好,学了就知道了!
3、报名课程的费用可以开发票吗?
深蓝学院所有课程都可以开具发票。您可以登录深蓝学院官网(https://www.shenlanxueyuan.com),进入个人“账户中心”,在线申请。
4、报名后怎么开始学习呢?
PC端:登录深蓝学院官网(https://www.shenlanxueyuan.com),进入“个人中心”或“我的课程” 的课程即可开始学习。课程中包含讲师讲解的视频、课件、代码、作业及其它学习资料。建议在PC端学习体验更好。
如果想缓存视频,可下载深蓝学院APP。
5、可以跟讲师直接交流吗?
报名课程后添加课程对应的班主任微信,由其邀请加入微信答疑群。在答疑群内,您可以直接跟讲师和其他同学讨论交流。
报名后在对应的课程详情页,可查看对应的班主任微信。
6、学习形式和学习周期是怎样的?
为保证学习质量方便同学们反复观看,本课程采用录播形式。建议同学们登录深蓝学院PC端官网体验更佳。
7、课程有有效期吗?
为了督促同学们学习,保证学习效率,学院的课程有效期均为一年,当课程有效期截止后将不再支持观看视频、下载课件等课程服务及操作。若同学们依旧想观看视频和下载课件,建议可选择续费本课程。需要提醒大家的是,课程答疑、作业批改&讲评等课程相关服务期从报名加入课程后开始计算至少保证三个月。
8、作业会提供参考答案吗?
不提供参考答案。当每章作业截止提交后,会解锁作业思路讲解。我们希望引导大家培养独立思考的习惯和敢于动手实践的勇气,以便尽快适应实际工作中解决问题的模式。做作业过程中,如果有任何困惑和问题,可以在课程讨论区和交流群内提问解决。
其他问题请咨询客服

添加时请备注【ChatGPT】
课程预览
大语言模型基础:理论与实践
















