
BEV感知理论与实践
全面梳理BEV感知算法及其发展脉络
细致讲解各类代表性算法的代码实现
分享BEV落地的工程实践经验
 讲师:傅东旭
讲师:傅东旭 讲师:刘兰个川(Patrick Liu)
讲师:刘兰个川(Patrick Liu)

对课程有疑问? 点击视频立即观看课程介绍!
 您已经是《BEV感知理论与实践》-学员,是否购买最新一期?
您已经是《BEV感知理论与实践》-学员,是否购买最新一期?

- 本课程包括:
- 3个月群内答疑,讲师助教及时解答
- 课程有效期为1年,建议合理规划学习
- 课程配有作业练习,助教一对一批改
- 班主任带班,严格督学,告别拖延
- 根据学习情况颁发结业证书、优秀学员证书
傅东旭
自动驾驶高级算法专家,历任百度自动驾驶高级研发工程师,纽劢科技L4部门研发负责人,商汤自动驾驶研发副总监。浙江大学控制系硕士,毕业至今拥有6年+的L4自动驾驶研发经验,擅长3D感知、定位建图和多传感器标定等技术。
刘兰个川(Patrick Liu)
前小鹏汽车自动驾驶AI团队负责人,在职期间带领团队从0到1搭建了自动驾驶的BEV感知大模型XNet,也参与了中国最大的自动驾驶智算中心“扶摇”的搭建和维护。在XNet技术的驱动下,小鹏城区辅助驾驶XNGP已经在旗舰SUV G9和旗舰轿跑P7i上落地。本科毕业于北京大学物理学院,博士毕业于密歇根大学安娜堡分校。在加入小鹏之前,曾在硅谷和圣地亚哥的多家科技公司任职。
BEV全称为Bird’s eye view(鸟瞰视角),BEV感知是将摄像头或雷达采集的视觉信息转换至鸟瞰视角进行相关感知的任务。通俗地讲,BEV感知相当于给自动驾驶开启了“上帝视角”,能够让车辆无遮挡的“看清”道路上的实况信息,进而在BEV视角下统一完成感知和预测任务。
在传统的image-view方案中,3D目标检测、障碍物实例分割、车道线分割、轨迹预测等各项感知任务互相分离,使得该方案下的自动驾驶算法需要串联多个子模块,极大增加了算法的开发、维护成本。而BEV感知能够让这些感知任务在一个算法框架下实现。
2023年,BEV感知方案在特斯拉、华为、小鹏等头部自动驾驶企业已量产落地。目前对BEV方案进行系统化梳理的教程依然较少,为了让同学们系统化地学习BEV感知的理论及其实践,深蓝学院联合业界资深工程师打磨推出了这门课程。
课程大纲
-
第1章:自动驾驶感知模型的演变
本章介绍了自动驾驶从L2到L2+功能需求发生了极大变化,由于传统感知算法的局限性和扩展性不佳,强烈的需求变化驱动了技术发展和感知模型的演变。随后补充讲解了重点模型Transformer的基础知识,以ViT和DETR为例介绍了Transformer的关键组件Self-Attention和Cross-Attention,为后续BEV感知模型视角转换章节的理解打好知识基础。
-
第2章:特征空间转换方法
BEV为多传感器融合提供了更加合适的特征空间,在多模态多任务结合方面提供了统一的优化目标,减少了规则化设计,可以提升在多场景下的泛化适应能力。其中,最为关键的环节是由2D图像平面到BEV空间平面的空间转换过程。在本章中介绍了当前主流的特征空间转换方法,包括IPM、2D-to-3D的深度估计方法LSS、3D-to-2D基于transformer的Sparse Query和Dense Query方法。
-
第3章:基于LSS的BEV感知模型原理
本章介绍了LSS系列的感知模型和算法各自的特点,Lift-Splat-Shoot提出了LSS,以预测视锥深度方式将2D图像特征转换到BEV空间视角;CaDDN在深度估计上加入显式监督来完成单目3D检测;BEVDet实现了多相机视角的LSS转换方法;BEVDet4D在BEVDet基础上支持了时序信息融合;M2BEV支持检测和分割多任务联合;BEVFusion在BEV空间上支持了多传感器融合;FastBEV在推理性能上做了进一步优化。
-
第4章:LSS-based BEV感知模型的工程实现
本章深入讲解了LSS感知模型的工程实现,从数据标注和预处理方面上讲解了数据“流”;在工程代码的框架上介绍了集大成的框架“流”;在模型设计上讲解了关于模型封装与算法流程的模型“流”,重点讲解了image-view encoder与LSS-view transform;最后在张量“流”环节,通过逐层调试查看LSS模型中张量的变化,学习模型的推理过程。
项目实践
-
Project 1 Vision Transformer
DETR是第一个将Transformer成功应用于目标检测的框架。该项目希望同学们实现Vision Transformer模型的结构和关键组件,并在COCO数据集做效果验证。通过该项目,同学们可以加深对自注意力机制、多头注意力等核心概念的理解和实现能力。

-
Project 2 Inverse Perspective Mapping
逆透视变换IPM (Inverse perspective mapping) 是将相机视角转换成鸟瞰图Bird’s View的一种方法。该项目让学生深入了解视图转换与IPM原理,通过编写透视投影代码,掌握其核心数学原理,并应用IPM将前视图映射到鸟瞰图中,理解其在自动驾驶中的应用。

-
Project 3 LSS特征空间转换
LSS (Lift-Splat-Shoot) 模型通过显式估计图像的深度信息,对采集到的环视图像进行特征提取,并根据估计出来的离散深度信息,实现图像特征向BEV特征的转换。该项目将实现LSS模型中的核心方法,并通过对输入图像的前向传播,观察特征空间的变换过程。
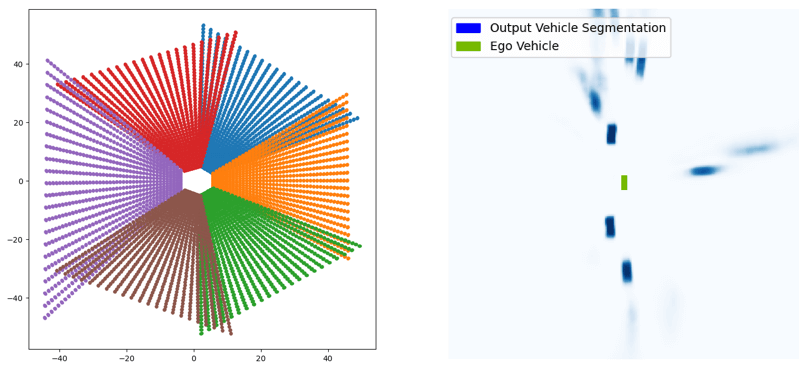
-
Project 4 Transformer特征空间转换
BEVFormer模型通过提取环视相机采集到的图像特征,并将提取的环视特征通过模型学习的方式转换到BEV空间,从而实现3D目标检测和地图分割任务。该项目将实现BEVFormer模型中的特征空间转换模块,让同学们掌握Transformer特征空间转换的关键步骤。
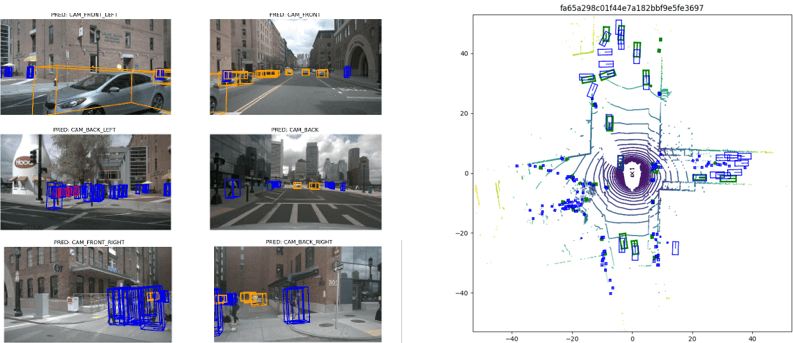
-
Final Project 图像与点云BEV空间特征融合
图像与点云的多模态融合是自动驾驶感知中的常见任务。该项目将实现图像与点云在BEV空间的特征融合,主要包含隐式对齐特征以及SE通道注意力模块,从而实现对图像BEV与点云BEV的加强融合。在nuscenes-mini数据集上完成推理,观察BEV特征的定性效果和推理的定量效果。
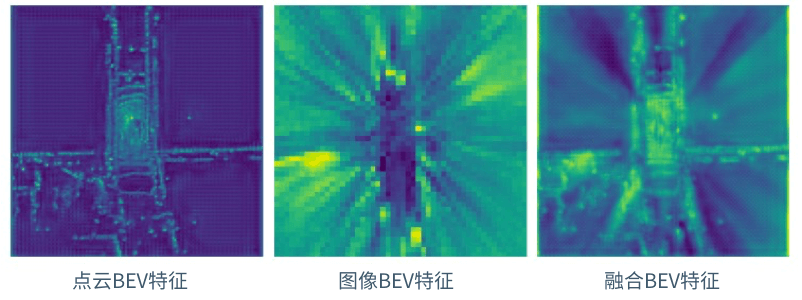
-
实车演示
通过6路相机获取图像,编码到BEV空间下,通过BEV感知算法实现环视3D目标检测与速度预测。同时,将BEV感知算法通过TensorRT推理加速,融入Apollo系统,部署到深蓝学院的自动驾驶实训车辆上(由于需要车辆硬件支持,实车部署的内容,本次课程只展示效果,但会带着大家完成BEV感知基于TensorRT的推理加速)。
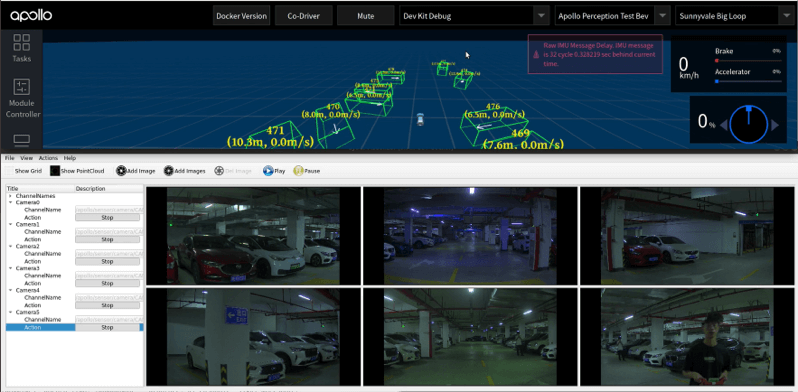
学习收获
- 1掌握BEV感知的发展脉络:2D-to-3D方法以及3D-to-2D方法
- 2熟悉BEV感知极具代表性的算法原理:BEVDet / BEVPoolv2 / BEVFormer
- 3学习BEV模型工程实现的数据流、框架流、模型流和张量流
- 4积累BEV在征程芯片以及NVIDIA芯片上实际部署的经验
课程适合谁学习
- 希望从事自动驾驶视觉感知研发的在校生
- 企业中人工智能算法设计与工程开发的工程师
- 自动驾驶企业中其他方向的研发工程师
基础&设备要求
-
熟悉Python编程
-
熟悉常见的深度学习模型,尤其是transformer及其attention机制
-
具备熟练阅读英文paper的能力
-
硬性要求: 12G及以上的显存
-
建议设备: RTX3090及以上的显卡;团队尝试过8个RTX3090显卡从零开始训练BEV模型,训练时长为5天;为了减少训练时间,学院也会同步提供预训练的BEV模型
全方位的学习服务
个性化增值服务,学习有保障更高效
-
 作业批改
作业批改
作业批改 助教1V1批改作业,定期针对作业中的“通病”进行点评
-
 结业证书
结业证书
结业证书 本课程将根据作业完成情况评选结业学员及优秀学员,颁发证书
-
 实时答疑
实时答疑
实时答疑 讲师和助教微信群答疑,及时解决大家遇到的问题
-
 班班督学
班班督学
班班督学 班主任全程带班,不定时“关照”未交作业的同学,克服拖延
- 1:开课仪式
-
第1章: 自动驾驶感知模型的演变 5节课程1篇阅读材料·1次作业·1小时27分钟
本章介绍了自动驾驶从L2到L2+功能需求发生了极大变化,由于传统感知算法的局限性和扩展性不佳,强烈的需求变化驱动了技术发展和感知模型的演变。随后补充讲解了重点模型Transformer的基础知识,以ViT和DETR为例介绍了Transformer的关键组件Self-Attention和Cross-Attention,为后续BEV感知模型视角转换章节的理解打好知识基础。
- 2:【课件】感知模型的演变
-
第1节: 自动驾驶功能需求的变化
- 免费 3:【视频】章节内容介绍
-
第2节: 【视频】L2与L2+的感知系统
- 免费 4:【视频】L2与L2+的感知系统
-
第3节: Telsa如何解决L2+感知需求
- 免费 5:【视频】Telsa如何解决L2+感知需求
-
第4节: 补充:self-attention与cross-attention
- 6:【课件】self-attention与Cross-attention
- 7:【视频】详细讲解Transformer中的Attention
- 8:【视频】视觉Transformer中的self-attention与Cross-attention
-
第5节: 实践:ViT中的Attention
- 9-1:Project 1 Vision Transformer
- 9-2:【实践】Project 1 Vision Transformer
- 9-3:Project 1 Vision Transformer
- 9-4:【作业】Project 1 Vision Transformer
-
第2章: 特征空间转换方法 7节课程2篇阅读材料·3次作业·1小时13分钟
BEV为多传感器融合提供了更加合适的特征空间,在多模态多任务结合方面提供了统一的优化目标,减少了规则化设计,可以提升在多场景下的泛化适应能力。其中,最为关键的环节是由2D图像平面到BEV空间平面的空间转换过程。在本章中介绍了当前主流的特征空间转换方法,包括IPM、2D-to-3D的深度估计方法LSS、3D-to-2D基于transformer的Sparse Query和Dense Query方法。
- 10:【课件】L2 View Transformation
-
第1节: 为什么BEV是更合适的特征空间
- 11:【视频】为什么BEV是更合适的特征空间
-
第2节: LSS(2D to 3D/从底向上):基于深度分布估计的方法
- 12:【视频】IPM与LSS特征空间转换方法
-
第3节: Transformer(3D to 2D/从顶向下):基于注意力机制的方法
- 13:【视频】Transformer特征空间转换方法
-
第4节: 本章小结
- 14:【视频】本章小结
-
第5节: 实践:IPM特征空间变换
- 15-1:【实践】Project 2 IPM空间转换实践
- 15-2:【作业】project 2 IPM空间转换实践
- 15-3:Project 2 IPM空间转换实践作业问题汇总
-
第6节: 实践:LSS特征空间变换
- 16-1:【实践】Project 3 LSS特征空间转换
- 16-2:【实践】Project 3 LSS特征空间转换
- 16-3:【作业】Project 3 LSS特征空间转换
- 16-4:【作业思路】Project 3 LSS特征空间转换实践作业思路
-
第7节: 实践:Transformer特征空间变换
- 17-1:【实践】Project 4 Transformer特征空间转换
- 17-2:【实践】Project 4 Transformer特征空间转换
- 17-3:【作业】Project 4 Transformer特征空间转换
- 17-4:【作业思路】Project 4 Transformer特征空间转换
-
第3章: 基于LSS的BEV感知模型原理 7节课程·1小时52分钟
本章介绍了LSS系列的感知模型和算法各自的特点,Lift-Splat-Shoot提出了LSS,以预测视锥深度方式将2D图像特征转换到BEV空间视角;CaDDN在深度估计上加入显式监督来完成单目3D检测;BEVDet实现了多相机视角的LSS转换方法;BEVDet4D在BEVDet基础上支持了时序信息融合;M2BEV支持检测和分割多任务联合;BEVFusion在BEV空间上支持了多传感器融合;FastBEV在推理性能上做了进一步优化。
- 18:【资料】BEV实践环境配置
- 19:【课件】基于LSS的BEV模型原理
-
第1节: 内容引入
- 20:【视频】内容引入
-
第2节: CaDNN算法
- 21:【视频】CaDNN算法
-
第3节: BEVDet系列算法:BEVDet与BEVDet4D
- 22-1:【视频】BEVDet系列算法:BEVDet原理与细节实现
- 22-2:【视频】BEVDet系列算法:BEVDet4D基本思想
-
第4节: LSS-based 方法:M2BEV
- 23:【视频】M^2BEV:第一个支持多任务的算法
-
第5节: LSS-based 方法:BEVFusion
- 24:【视频】BEVFusion:图像与激光雷达融合的多传感器融合算法
-
第6节: LSS-based 方法:FastBEV
- 25:【视频】面向工程设计的FastBEV
-
第7节: LSS系列算法小结
- 26:【视频】LSS系列方法小结
-
第4章: LSS-based BEV感知模型的工程实现 4节课程·4小时27分钟
本章深入讲解了LSS感知模型的工程实现,从数据标注和预处理方面上讲解了数据“流”;在工程代码的框架上介绍了集大成的框架“流”;在模型设计上讲解了关于模型封装与算法流程的模型“流”,重点讲解了image-view encoder与LSS-view transform;最后在张量“流”环节,通过逐层调试查看LSS模型中张量的变化,学习模型的推理过程。
- 27:【课件】BEV模型实现讲解与实践 Part I
-
第1节: 内容概览:从感知任务需求到工程实现
- 28:【视频】BEV工程实现:数据流、框架流、模型流与张量流
-
第2节: 从BEV感知任务到数据拆解:数据“流”
- 29-1:【视频】数据“流”:标注数据-数据转换-数据训练
- 29-2:【视频】数据“流”:标注数据
- 29-3:【视频】数据“流”:数据转换
- 29-4:【视频】数据“流”:数据集的准备与读取
-
第3节: 从BEV工程实现到框架拆解:框架“流”
- 30-1:【视频】框架“流”:训练pipeline
- 30-2:【视频】框架“流”:configs文件
- 30-3:【视频】框架“流”:模型的Registry&Hook
- 30-4:【视频】框架“流”小结
-
第4节: 从BEV算法设计到模型拆解:模型“流”与张量“流”
- 31-1:【课件】模型流与张量流
- 31-2:【视频】模型“流”&张量“流”:算法设计-模型封装实现-模型推理张量
- 31-3:【视频】模型“流”&张量“流”:image-view encoder
- 31-4:【视频】LSS-view transform
- 31-5:【视频】BEV空间特征及任务head
-
第5章: LSS-based BEV感知模型在地平线征程芯片上的部署 4节课程·1小时22分钟
本章以BEVDet为例介绍了BEV感知模型在征程芯片j5上的部署与推理加速,介绍了地平线OpenExplorer工具开发包,重点讲解了BEVDet浮点模型的搭建流程,模型量化中的流程细节与注意事项,精度Debug工具的使用,模型量化后的可视化效果,最后介绍了模型编译和上板性能测评。
- 32-1:基于征程芯片的BEV算法部署:BEVDet为例
- 32-2:【资料】BEVDet环境配置与实践
-
第1节: OpenExplorer开发包介绍
- 33:【视频】OpenExplorer开发包介绍
-
第2节: 搭建浮点模型
- 34:【视频】搭建浮点模型
-
第3节: 模型量化
- 35:【视频】模型量化
-
第4节: 模型编译与上板
- 36:【视频】模型编译与上板
-
第6章: 基于Transformer的BEV模型原理 2节课程·1小时27分钟
本章介绍了基于Transformer系列的BEV模型和一系列代表算法,主要分为稠密Query和稀疏Query的BEV特征表示。稠密BEV特征以BEVFormer为代表,可以支持时序融合和多任务实现;稀疏Query以PETR系列为代表,PETR优化了Cross Attention并引入3D位置编码;PETRv2支持位置编码的时序融合和多任务实现;Stream PETR提出了Object-Centric时序融合;FUTR3D实现了多传感器融合等,最后总结了LSS与Transformer两种视角转换方式之间的异同点。
- 37:【课件】基于Transformer的BEV模型原理
-
第1节: Transformer-based方法的引入
- 38:【视频】Transformer-based方法的引入
- 39-1:【视频】基于稠密Query的BEV表示:BEVFormer
- 39-2:【视频】BEVFormer的实现细节
- 40:【视频】基于稀疏Query的BEV表示:PETR系列
- 41:【视频】基于稀疏Query的BEV表示:FUTR3D
-
第2节: View Transformation各类方法的总结
- 42:【视频】BEV动静态元素检测任务模型总结
-
第7章: Transformer-based BEV感知模型的工程实现 7节课程1篇阅读材料·1次作业·2小时55分钟
本章深入讲解了以BEVFormer为代表的Transformer-basedBEV感知模型的工程实现。深入讲解了Transformer-based方法3D-to-2D的转换思路,在模型设计上讲解了关于模型封装与算法流程的模型“流”,着重讲解了BEVFormer Encoder部分的TemporalSelfAttention、SpatialCrossAttention和Decoder部分的DetectionTransformerDecoder;在张量“流”环节,通过逐层调试查看BEVFormer模型中张量的变化,学习模型的推理过程。
- 43:【课件】BEVFormer模型实现讲解与实践
-
第1节: 内容概览:从算法设计到模型推理张量
- 44:【视频】内容概览
-
第2节: Transformer-based 3D-to-2D的实现思路
- 45:【视频】Transformer-based 3D-to-2D 基本思路
-
第3节: BEVFormer的数据流
- 46:【视频】BEVFormer的数据流
-
第4节: BEVFormer的模型封装
- 47:【视频】BEVFormer的模型封装实现
-
第5节: BEVFormer Encoder的实现
- 48-1:【视频】BEVFormerEncoder:TemporalSelfAttention(上)
- 48-2:【视频】BEVFormerEncoder:TemporalSelfAttention(下)
- 48-3:【视频】SpatialCrossAttention
-
第6节: Detection Transformer Decoder的实现
- 49:【视频】DetectionTransformerDecoder
-
第7节: 实践:图像与点云BEV空间特征融合实践
- 50-1:【实践】Final Project 图像与点云BEV空间特征融合
- 50-2:【实践】图像与点云BEV空间特征融合
- 50-3:【选做作业】Final Project 图像与点云BEV空间特征融合实践
-
第8章: Transformer-based BEV模型在Nvidia芯片上的部署 1节课程·53分钟
本章介绍了BEV感知模型在Nvidia芯片上的部署与推理加速,介绍了模型在部署时的算力要求和实时性需求。重点讲解了BEVFormer模型的部署过程,其中包括由pth模型转换为ONNX的代码流程,由ONNX转换为TensorRT模型的流程细节和注意事项,以及如何使用TensorRT工具对模型进行量化,最后对模型的量化结果做加速推理测试。
-
第1节: 基于Nvidia芯片的BEVFormer推理加速
- 51:【视频】训练好的模型转ONNX
- 52:【视频】ONNX转TensorRT模型
-
第9章: BEV for Occupancy 3节课程·3小时33分钟
本章介绍了Occupancy的任务定义以及Benchmark的建立。根据技术脉络,着重介绍了6个关于Occupancy的相关工作。MonoScene第一次通过2D实现单目3D语义场景补全;VoxFormer提出两阶段的单目3D语义场景补全;TPVFormer拓展到多相机Occupancy预测;OpenOccupancy与SurroundOcc重点提出了稠密数据集的构建流程与自动化生成过程;Occ3D优化了自动标注流程,同时提出了Occlusion Reasoning的概念等。
- 53:【课件】从BEV到Occupancy
-
第1节: 任务定义
- 54:【视频】任务定义
-
第2节: Occupancy方法:MonoScene, VoxFormer, TPVFormer,OpenOccupancy, SurroundOcc, Occ3D
- 55:【视频】MonoScene
- 56:【视频】VoxFormer
- 57:【视频】TPVFormer
- 58:【视频】OpenOccupancy
- 59:【视频】SurroundOcc
- 60:【视频】Occ3D
-
第3节: 总结
- 61:【视频】总结
-
第10章: BEV for Mapless 6节课程·3小时13分钟
本章介绍了无图方案,将局部路网结构下的感知从高精地图构建转变为了实时感知,逐渐接近高精地图方案,达到量产能力。重点介绍了几种模型:HDMapNet用语义分割实现多相机的局部地图构建,进行矢量元素检测;STSU使用贝塞尔曲线与连接矩阵构建局部地图;VectorMapNet与MapTR使用polyline+点集构建地图等。
- 62:【课件】从BEV到Mapless
-
第1节: 高精地图介绍
- 63:【视频】高精度地图介绍
-
第2节: HDMapNet:在BEV空间上做⽮量地图元素检测
- 64:【视频】HDMapNet感知局部矢量地图
-
第3节: STSU:用贝塞尔曲线表达矢量地图
- 65:【视频】STSU:贝塞尔曲线表达矢量地图
-
第4节: VectorMapNet:用Polyline与点集构建矢量地图
- 66:【视频】VectorMapNet:用Polyline与点集构建矢量地图
-
第5节: MapTR:实时且精度更高的方案
- 67:【视频】MapTR:更接近量产落地的方案
-
第6节: 本章小结
- 68:【视频】Mapless方法总结
-
第11章: BEV for End-to-End 3节课程·3小时1分钟
端到端的自动驾驶由BEV扩展而来,也是当前研究和应用的热点,技术不断蓬勃发展,螺旋上升。LSS首次在视觉BEV特征上做出Perception+Planning结合;FIERY在视觉BEV特征上支持了Perception+Prediction;MUTR3D首次实现了多相机端到端Perception+Tracking;UniAD将所有任务以Query形式表达,实现了Perception+Prediction+Planning等。
- 69:【课件】从BEV到End to End
- 70:【视频】从BEV到End-to-End
-
第1节: FIERY:Perception + Prediction
- 71:【视频】从BEV到E2E:FIERY
-
第2节: MUTR3D:Perception + Tracking
- 72:【视频】从BEV到E2E:MUTR3D
-
第3节: UniAD:Perception + Planning
- 73:【视频】从BEV到E2E:UniAD
-
第12章: 自动驾驶中的4D标注 1小时2分钟
本章介绍了数据标注随着感知算法迭代以及轻地图方案的发展而发生的变化,介绍了2D与3D数据的生产方式、成本与标注方式;4DLabel标注的发展背景与其在重感知轻地图路线中逐渐发挥的作用;最后介绍了在实际自动驾驶中面临的数据问题,包括corner case、标注复杂与跨车泛化性等难题和解决方案。
- 74:【课件】自动驾驶中的4D Label概述
- 75:【视频】4D Label背景介绍
- 76:【视频】4DLabel在自动驾驶中的作用
- 77:【视频】自动驾驶中的数据问题
课程讨论区
已累计讨论26495个问题
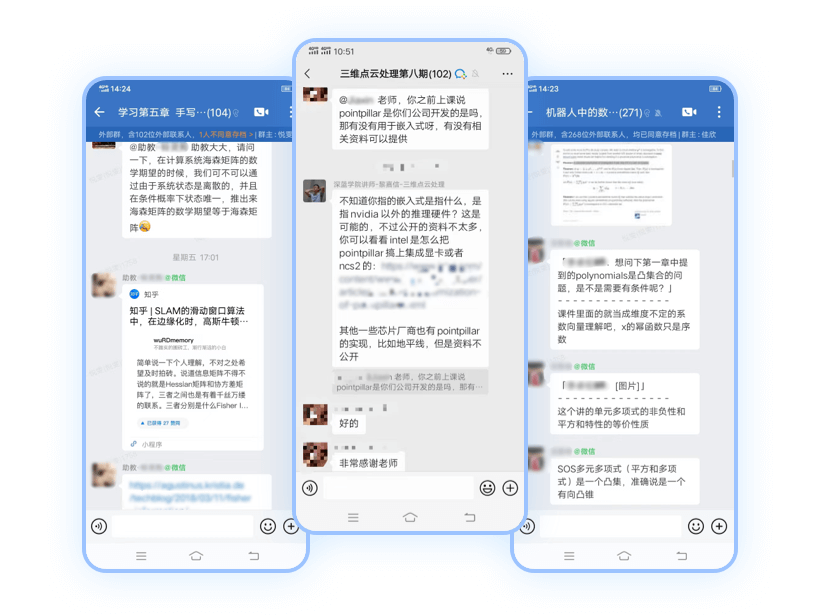
课程配备专属讨论区,不仅有讲师、助教全程答疑,更能与同学们交流讨论,在思维碰撞中加深理解
在课程中随想随问,同学们的问题也可能启发到你

在课程讨论区,和684位同学一起探讨更多问题···
作业批改
已累计批改4951份作业
助教一对一批改作业,定期针对作业中的问题进行评讲
结业证书
课程根据作业完成情况评选结业学员及优秀学员,颁发证书
优秀学员更能获得额外购课优惠

班班督学
班班、助教、讲师全程带班,日常答疑解惑
FAQ
1、课程可以试听吗?
可以,您可以联系客服领取试听内容,根据试听的效果决定是否报名。
2、报名课程后,如果不满意,可以退款吗?
我们承诺: 报名后7天内且学习进度停留在第一章节的内容可以无条件全额退款,若您的学习进度超过第一章或报名时间超过7天将不再支持退款哦。课好不好,学了就知道了!
3、报名课程的费用可以开发票吗?
深蓝学院所有课程都可以开具发票。您可以登录深蓝学院官网(https://www.shenlanxueyuan.com),进入个人“账户中心”,在线申请。
4、报名后怎么开始学习呢?
PC端:登录深蓝学院官网(https://www.shenlanxueyuan.com),进入“个人中心”或“我的课程” 的课程即可开始学习。课程中包含讲师讲解的视频、课件、代码、作业及其它学习资料。建议在PC端学习体验更好。
如果想缓存视频,可下载深蓝学院APP。
5、可以跟讲师直接交流吗?
报名课程后添加课程对应的班主任微信,由其邀请加入微信答疑群。在答疑群内,您可以直接跟讲师和其他同学讨论交流。
报名后在对应的课程详情页,可查看对应的班主任微信。
6、学习形式和学习周期是怎样的?
为保证学习质量方便同学们反复观看,本课程采用录播形式。建议同学们登录深蓝学院PC端官网体验更佳。
7、课程有有效期吗?
为了督促同学们学习,保证学习效率,学院的课程有效期均为一年,当课程有效期截止后将不再支持观看视频、下载课件等课程服务及操作。若同学们依旧想观看视频和下载课件,建议可选择续费本课程。需要提醒大家的是,课程答疑、作业批改&讲评等课程相关服务期从报名加入课程后开始计算至少保证三个月。
8、作业会提供参考答案吗?
不提供参考答案。当每章作业截止提交后,会解锁作业思路讲解。我们希望引导大家培养独立思考的习惯和敢于动手实践的勇气,以便尽快适应实际工作中解决问题的模式。做作业过程中,如果有任何困惑和问题,可以在课程讨论区和交流群内提问解决。
其他问题请咨询客服

添加请备注【BEV】
课程预览
BEV感知理论与实践
















