



课程价格 :
¥599.00
剩余名额
0
-

学习时长
8周/建议每周至少6小时
-

答疑服务
专属微信答疑群/讲师助教均参与
-

作业批改
课程配有作业/助教1V1批改
-

课程有效期
一年/告别拖延,温故知新
课程价格:
¥599.00
预约下一期 *课程已报满,可预约下一期
 支持花呗分期
支持花呗分期
*课程已报满,可预约下一期




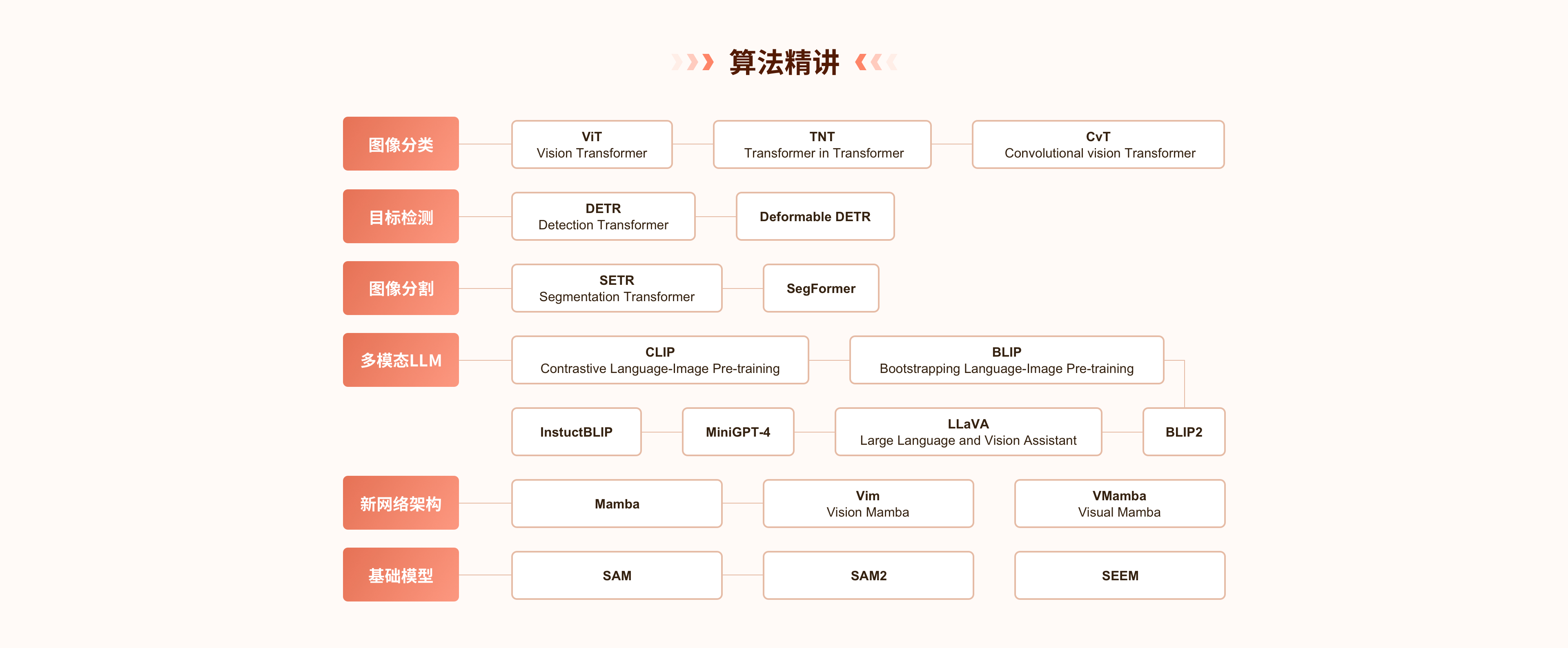





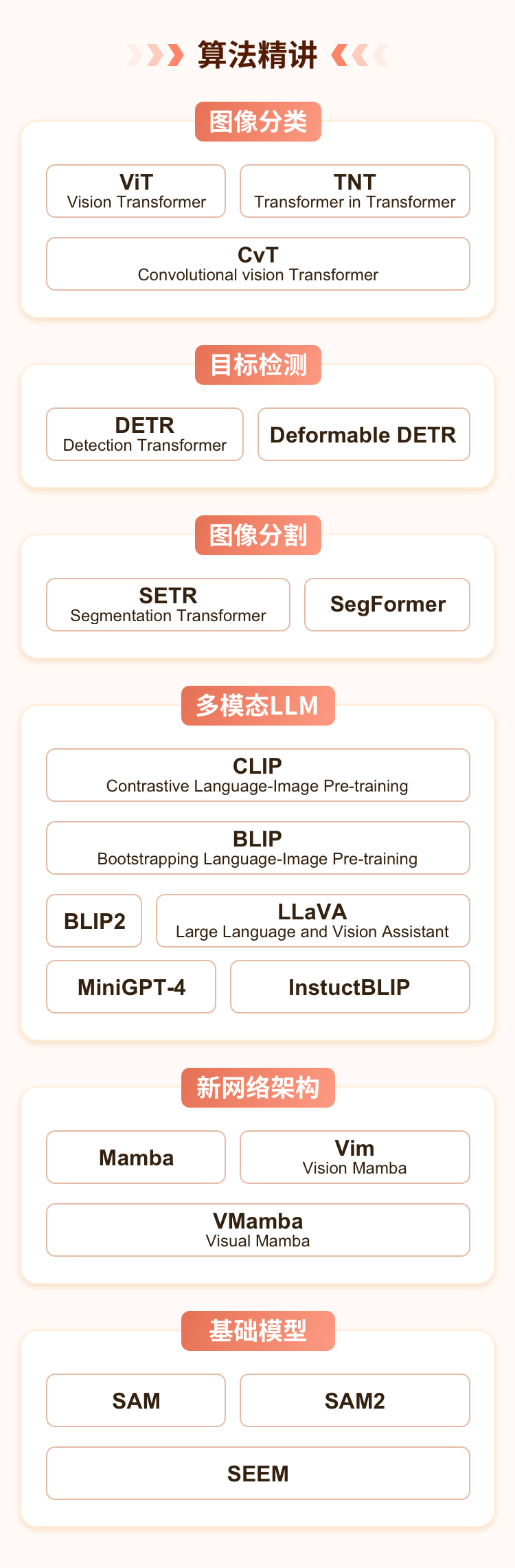

- 1-1:开班典礼
- 1-2:【课件】Transformer in Vision课程介绍
- 2:【视频】Transformer in Vision课程介绍
- 第1章: Transformer基础知识介绍
- 3:【课件】第一章讲义-Transformer基础知识介绍
- 第1节: CNN与Transformer对比
- 4:【视频】CNN 与 Transformer 对比
- 第2节: 注意力机制基础
- 5:【视频】注意力机制基础
- 第3节: Transformer基本原理
- 6:【视频】 Transformer 基本原理
- 第4节: 本章小结
- 7:【视频】本章小结
- 第5节: 本章作业:Transformer 多头注意力模块实现与调试
- 8:【视频】本章作业
- 9-1:作业说明文档
- 9-2:【作业】Transformer 多头注意力模块实现与调试
- 9-3:作业代码文件
- 9-4:作业思路讲解
- 第2章: Transformer在图像分类中的应用
- 10:【课件】第二章讲义-Transformer 在图像分类中的应用
- 第1节: 图像分类数据集介绍
- 11:【视频】图像分类数据集
- 第2节: 基于CNN的图像分类模型
- 12:【视频】基于CNN的图像分类
- 第3节: 基于Transformer的图像分类模型
- 免费 13:【视频】基于Transformer的图像分类算法
- 免费 14:【视频】ViT算法精讲
- 免费 15:【视频】TNT算法精讲
- 免费 16:【视频】CvT算法精讲
- 第4节: 本章小结
- 17:【视频】本章小结
- 第5节: 本章作业:基于TNT模型的图像分类任务
- 18:【视频】本章作业
- 19-1:作业说明文档
- 19-2:【作业】基于TNT模型的图像分类任务
- 19-3:作业思路讲解
- 第3章: Transformer在目标检测中的应用
- 20:【课件】第三章讲义-Transformer 在目标检测中的应用
- 第1节: 目标检测基本知识
- 21:【视频】 目标检测基础
- 第2节: CNN-based目标检测
- 22:【视频】基于CNN目标检测概述
- 23:【视频】两阶段目标检测
- 24:【视频】一阶段目标检测
- 第3节: Transformer-based目标检测
- 25:【视频】基于Transformer的目标检测
- 第4节: 本章小结
- 26:【视频】本章小结
- 第5节: 本章作业:基于 VisDrone 数据集的 DETR 模型训练
- 27:【视频】本章作业
- 28-1:作业说明文档
- 28-2:【作业】基于 VisDrone 数据集的 DETR 模型训练
- 28-3:作业思路讲解
- 第4章: Transformer在图像分割中的应用
- 29:【课件】第四章讲义-Transformer 在图像分割中的应用
- 第1节: 图像分割任务介绍及其相关数据集
- 30:【视频】 图像分割任务介绍及其相关数据集
- 第2节: 基于CNN的图像分割方法
- 31:【视频】基于CNN的图像分割方法
- 第3节: 基于Transformer的语义分割
- 32:【视频】基于 Transformer 的语义分割
- 第4节: 本章小结
- 33:【视频】本章小结
- 第5节: 本章作业:基于 ADE20K 数据集的 SETR 模型训练
- 34:【视频】本章作业
- 35-1:作业说明文档
- 35-2:【作业】基于 ADE20K 数据集的 SETR 模型训练
- 35-3:作业思路讲解
- 第5章: Transformer在多模态任务中的应用 (上)
- 36:【课件】第五章讲义-Transformer之多模态研发
- 第1节: 预备知识
- 37:【视频】预备知识
- 第2节: 多模态大模型代表性工作(上)
- 38:【视频】CLIP
- 39:【视频】 BLIP
- 40:【视频】 BLIP2
- 第3节: 本章小结
- 41:【视频】本章小结
- 第6章: Transformer在多模态任务中的应用 (下)
- 42:【课件】第六章讲义-Transformer之多模态研发II
- 第1节: 多模态大模型代表性工作(下)
- 43:LLaVA
- 44:MiniGPT-4
- 45:InstructBLIP
- 第2节: 基于VLM的下游应用
- 46:其他基于VLM的下游应用
- 第3节: 本章小结
- 47:【视频】本章小结
- 第4节: 本章作业:使用 llava_instruct_150k.json 数据微调 LLaVA
- 48:【视频】本章作业
- 49-1:作业说明文档
- 49-2:【作业】使用 llava_instruct_150k.json 数据微调 LLaVA
- 49-3:作业思路讲解
- 第7章: 新模型结构Mamba
- 50:【课件】第七章讲义-新网络架构Mamba
- 第1节: Mamba基础
- 51:【视频】Mamba基础
- 第2节: 基于Mamba的模型
- 52:【视频】Vision Mamba (Vim)
- 53:【视频】 Visual Mamba (VMamba)
- 第3节: 其他Mamba相关模型
- 54:【视频】其他Mamba相关模型
- 第4节: 本章小结
- 55:【视频】本章小结
- 第5节: 本章作业:基于 BraTS 2023 GLI 医疗数据集的 SegMamba 模型训练
- 56:【视频】本章作业
- 57-1:作业说明文档
- 57-2:【作业】基于 BraTS 2023 GLI 医疗数据集的 SegMamba 模型训练
- 57-3:作业思路讲解
- 第8章: 基于Transformer的视觉基础模型及其趋势
- 58:【课件】第八章讲义-Transformer基础模型及其展望
- 第1节: 基于Transformer的视觉基础模型
- 59: 【视频】 分割一切的Segment Everything Model(SAM)
- 60:【视频】 在视频里也能分割一切的SAM2
- 61: 【视频】Segment Everything Everywhere All at Once(SEEM)
- 第2节: 视觉基础模型的趋势
- 62:【视频】基础模型的趋势
- 第3节: 本章小结
- 63:【视频】本章小结
- 第4节: 本章作业:基于 COD10K 伪装物体检测数据集的 SAM 模型微调
- 64:【视频】本章作业
- 65-1:作业说明文档
- 65-2:【作业】基于 COD10K 伪装物体检测数据集的 SAM 模型微调
- 65-3:作业思路讲解
- 66-1:视觉Transformer第四期结业答疑问题收集
- 66-2:【视频】视觉Transformer理论与实践第四期结业答疑直播




























