课程价格 :
¥799.00
剩余名额
0
-

学习时长
8周/建议每周至少6小时
-

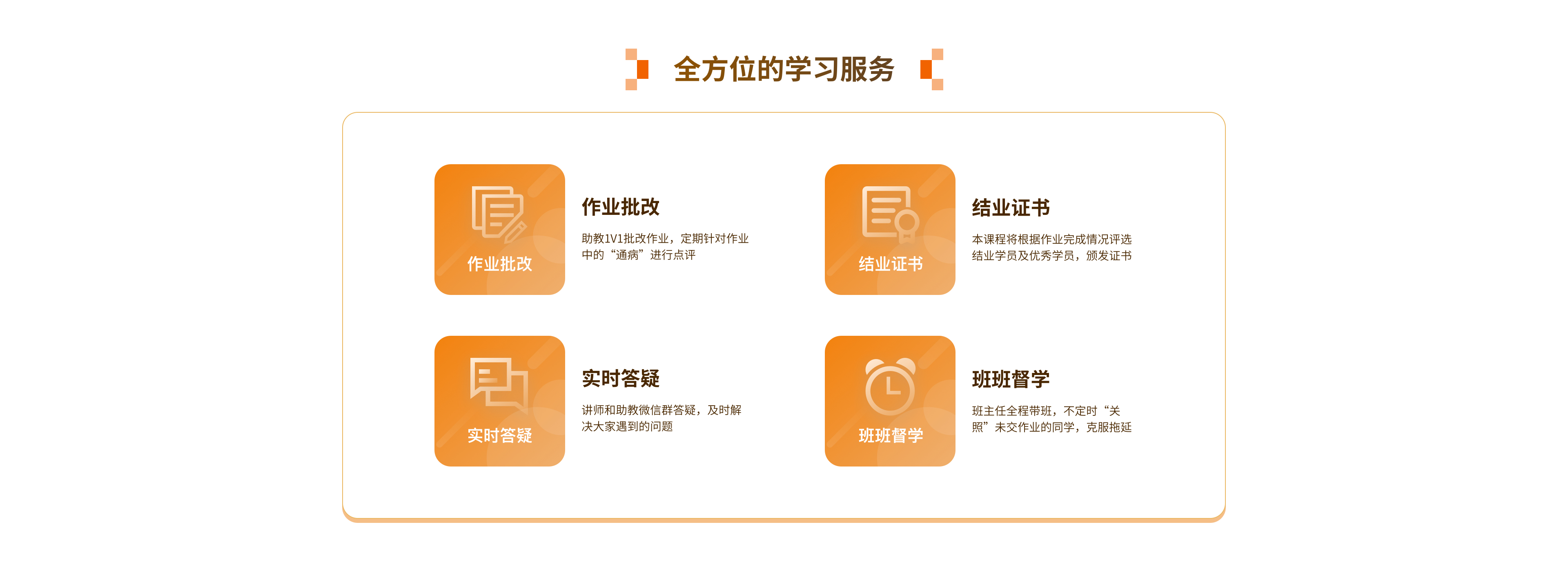
答疑服务
专属微信答疑群/讲师助教均参与
-

作业批改
课程配有作业/助教1V1批改
-

课程有效期
一年/告别拖延,温故知新
课程价格:
¥799.00
预约下一期 *课程已报满,可预约下一期
 支持花呗分期
支持花呗分期
*课程已报满,可预约下一期









- 第1章: 视觉语言导航与具身智能概论
- 1-1:【资料】第一章预习内容
- 1-2:【课件】VLN-Lecture1-VLN Intro
- 第1节: Embodied AI和VLN导论
- 2:【视频】Embodied AI与VLN导论
- 第2节: VLN的前置基础(CV、NLP)
- 免费 3:【视频】 VLN的前置基础
- 第3节: VLN架构的早期方法
- 免费 4:【视频】VLN架构的早期方法
- 第4节: VLN架构的高级方法
- 免费 5:【视频】VLN架构的高级方法
- 第5节: 数据集和评估指标
- 6:【视频】数据集合评估指标
- 第6节: 挑战与未来方向
- 7:【视频】挑战与未来方向
- 第2章: VLN数据集与任务设定
- 8-1:【资料】第二章预习内容
- 8-2:【课件】VLN-Lecture2-VLN Datasets
- 第1节: 视觉语言导航任务概述
- 9:【视频】视觉语言导航任务概述
- 第2节: 核心VLN数据集详解(R2R、VLN-CE、R4R、CVDN、HANNA、SOON、REVERIE)
- 10:【视频】核心VLN数据详解
- 第3节: 核心VLN任务与模型(单指令导航、目标驱动导航、对话导航)
- 11:【视频】核心VLN任务与模型
- 第4节: 从数据集与任务的角度看VLN的未来
- 12:【视频】从数据集与任务的角度看VLN的未来
- 第5节: Project1:Matterport3D模拟器与R2R数据集
- 13-1:Project1:Matterport3D模拟器 与 R2R数据集
- 13-2:Project1:作业说明
- 13-3:【视频】作业说明
- 第3章: 基础结构设计:序列与融合模型
- 14:【课件】VLN-Lecture3-Base Architecture
- 第1节: 核心VLN架构:序列模型(R2R)
- 15:【视频】核心VLN架构:序列模型
- 第2节: 核心VLN架构:融合模型(REVERIE、SOON、CVDN、HANNA)
- 16:【视频】核心VLN架构:融合模型
- 第3节: 跨模态融合与高级模型(Recurrent VLN-BERT、HAMT)
- 17:【视频】跨模态融合与高级模型
- 第4节: 总结:VLN模型的演化
- 18:【视频】总结:VLN模型的演化
- 第4章: 学习范式:模仿学习与强化学习
- 19:【课件】VLN-Lecture4-Learning approaches
- 第1节: 知识回顾与过渡
- 20:【视频】知识回顾
- 第2节: VLN中的模仿学习与强化学习(Speaker-Follower、RCM)
- 21-1:【视频】VLN的学习范式
- 21-2:【视频】模仿学习范式
- 21-3:【视频】强化学习
- 第3节: IL/RL混合方法(VLN-R1)
- 22:【视频】混合方法
- 第4节: 本章总结
- 23:【视频】本章总结
- 第5节: Project2:Habitat模拟器与VLN-CE数据集
- 24-1:【作业】Project 2:Habitat模拟器 与 VLN-CE数据集
- 24-2:【文档】作业说明
- 第5章: 视觉语言预训练技术
- 第1节: 模型复习与过渡
- 第2节: 预训练范式
- 第3节: 基础预训练模型与方法
- 第4节: 经典架构(PREVALENT、Recurrent VLN-BERT、Airbert)
- 第5节: 高级架构(BEVBert)
- 第6节: 从预训练到微调
- 第6章: VLN与大语言模型(LLM)的融合
- 第1节: 一个新的核心认知 LLM
- 第2节: LLM解锁的基础能力与相关工作(NavGPT、MiC)
- 第3节: 通过微调增强导航能力(NaVid)
- 第4节: 关键挑战与总结
- 第5节: Project3:REVERIE数据集与DUET模型
- 第7章: 空中视觉语言导航(Air VLN)
- 第1节: 具身导航从地面到天空的演进
- 第2节: 空中导航的独特挑战
- 第3节: Air VLN的架构与模型(UAV-VLN、VLFly、OpenFly)
- 第4节: Air VLN的生态系统(仿真环境、模拟器与数据)
- 第5节: Project4:AirSim 模拟器与 AirVLN 任务
- 第8章: 机器人中的视觉语言导航应用
- 第1节: 从仿真到物理世界
- 第2节: 前沿架构解析(GVNav、SmartWay、Navid、Uni-Navid)
- 第3节: 课程总结
实践项目介绍
项目1:R2R任务
R2R(Room-to-Room)是首个大规模视觉语言导航数据集,基于Matterport3D室内扫描场景,提供自然语言指令与实际路径对齐标注,涵盖多样化建筑布局与复杂空间关系,用于训练和评估智能体在真实三维室内环境中根据语言指令完成导航任务的能力,是VLN研究的重要基准。
基于真实Matterport3D室内场景构建
提供自然语言指令与离散导航路径对齐标注
场景多样,适合VLN基线模型训练与评测

项目2:VLN-CE任务
VLN-CE(Vision-Language Navigation in Continuous
Environments)将R2R扩展至连续动作空间,提供真实感物理碰撞与运动约束。基于Matterport3D和Habitat平台,支持物理可行的连续运动与传感输入模拟。相比离散环境,它更贴近现实机器人导航,强调感知、避障与路径规划的综合能力评估。
扩展R2R至连续动作空间,更贴近真实机器人导航
使用高精度3D网格并考虑物理可行性
强调感知、避障与路径规划的综合能力

项目3:REVERIE任务
REVERIE(Remote Embodied Visual Referring Expression in Real Indoor
Environments)将视觉导航与物体定位结合,要求智能体在复杂室内场景中根据远程描述找到特定目标物品。数据基于Matterport3D,包含丰富的自然语言指令与目标物体标注,任务难度高,需要结合全局导航规划与局部视觉识别。
将视觉导航与精细物体定位任务结合
提供自然语言远程描述与物体标注
评估智能体的全局路径规划与局部识别能力

项目4:AerialVLN任务
AerialVLN是首个低空无人机视觉语言导航数据集,涵盖多样城市与自然场景,结合航拍视觉特征与自然语言导航指令,强调三维空间理解与飞行路径规划能力。任务场景中存在地标识别、飞行高度控制和避障需求,推动了具身智能体在空中环境中的多模态导航研究。
首个低空无人机视觉语言导航数据集
结合航拍视觉与自然语言指令
涵盖高度控制、避障与三维空间理解任务