

- 活动内容
-
三维场景感知与理解是计算机视觉的一个重要研究方向。相比于二维图像,三维点云包含了更加丰富的几何、形状和结构信息,为场景感知与理解提供了更多可能性。近年来,随着三维传感器技术的快速发展,三维数据呈现爆发式增长,三维场景感知与理解也被越来越广泛地应用于智能驾驶、机器人、增强现实等领域。
第15期CSIG图像图形学科前沿讲习班(Advanced Lectures on Image and Graphics,简称IGAL)将于2019年12月28日-29日在北京·中国科学院自动化研究所举办,本期讲习班主题为“三维场景感知与理解”,围绕三维场景感知与理解,介绍其在相关领域的相关工作及最新进展。讲习班由上海交通大学卢策吾研究员担任学术主任,邀请三维场景感知与理解领域一线专家作特邀报告,使学员在了解学科前沿、提高学术水平的同时,增强与国内外顶尖学者的学术交流,了解产学研的发展动态发展趋势。
一.组织机构
主办单位:中国图象图形学学会
支持单位:深蓝学院
二.时间地点
时间:2019年12月28日-29日
地点:北京·中国科学院自动化研究所三层学术报告厅
三.学术主任
卢策吾,上海交通大学研究员,博士生导师。2016年获得国家青年千人计划。2017年被评为科学中国人杰出青年科学家,2018年被《麻省理工科技评论》评为中国35位35岁以下科技精英,2019年获“求是杰出青年学者奖”(近三年唯一AI方向)。发表CVPR/ICCV/PAMI等顶会顶刊60多篇。发表的“Image smoothing via L 0 gradient minimization”在近7年的1000多篇TOG文章中被引次数最高,TOG被引用次数最高。担任国际AI学术顶会CVPR2020领域主席,国际会议CVM 2018大会程序主席。顶级期刊《nature》人工智能方向审稿人。
四.报告嘉宾(按讲者姓氏拼音排序)
报告题目:深度学习与多视角几何模型融合的三维感知
报告摘要:计算机视觉中的几何视觉利用相机获取的多视角图像重建所观测场景的三维几何结构,在SLAM、无人系统、自动驾驶、机器人、虚拟现实/增强现实和场景分析等方面有重要应用。深度学习特别是深度卷积网络在特征学习与语义信息提取上有巨大优势,如何将数据驱动模型与多视角几何模型相结合成为研究热点。本报告将涵盖报告人针对此问题的一系列最新工作,包括如何在监督学习框架下进行单目深度估计、双目深度估计、多目深度估计,如何构建自监督学习框架以实现连续视频帧双目深度估计、具有几何约束的单目光流估计和双目-激光雷达数据的有效融合等。最后对于本领域的进一步发展进行讨论。
嘉宾简介:戴玉超,西北工业大学电子信息学院教授、博士生导师,陕西省信息获取与处理重点实验室主任。2005年、2008年和2012年分别获得西北工业大学学士、硕士和博士学位。2012年至2014年在澳大利亚国立大学计算机研究院从事博士后研究工作,2014年至2017年在澳大利亚国立大学工程研究院担任ARC DECRA学者。2017年入选中组部“千人计划”青年项目并加盟西北工业大学。主要研究工作集中在计算机视觉、图像处理、人工智能、深度学习等领域,包括三维场景重建、动态场景分析、多视角几何、深度学习、人机交互、无人驾驶、视觉导航等。已在IEEE TPAMI、IJCV、ICCV、CVPR、ECCV等国际期刊和会议上发表论文50余篇。先后获得IEEE CVPR 2012最佳论文奖(大陆高校30年来首次获得该奖项)、陕西省优秀博士论文、DICTA DSTO图像处理最佳基础贡献论文奖、CVPR非刚性结构与运动恢复挑战赛最佳算法奖、DICTA最佳学生论文奖、APSIPA-ASC最佳深度学习/机器学习论文奖和陕西省科技进步二等奖等奖项。主持和参与国家自然科学基金面上项目,澳大利亚研究委员会(ARC) DECRA项目,国家自然科学基金国际合作重点项目、科技部“新一代人工智能”重大专项、无人驾驶项目等。担任TPAMI、IJCV、T-NNLS、CVPR、ICCV、ECCV、ACM-MM等国际期刊和会议审稿人并担任WACV 2019/2020,ACM-MM 2019、ICME 2020等领域主席(Area Chair)。
报告题目:人体动态三维重建技术与应用
报告摘要:人体对象是视觉场景信息中最重要的部分,其具有复杂的纹理外观特性、非刚性形变和高动态特性。人体对象的动态三维重建可应用于全息三维影像通信、3D人体试衣、增强现实、安防视频人体行为分析、各类智能机器三维视觉分析、影视娱乐游戏等。近年随着三维视觉技术和深度学习网络技术的发展,IphoneX等智能手机新增加实时深度成像模组,HoloLens/Magic Leap One等AR设备的出现,5G网络的启动,人体动态三维重建的应用变得越发清晰。本报告回顾近20年动态人体三维重建技术的发展,总结多条技术脉络,包括基于多相机、基于单深度相机、基于单图像或单视频的人体重建方法,同时围绕重建的目标需求:精准、实时、便捷、大范围、语义化等5大目标进行技术阐述。
嘉宾简介:刘烨斌,清华大学自动化系长聘副教授,博士生导师。分别于2002年和2009年在北京邮电大学、清华大学自动化系获得工学学士和工学博士学位。2009年在清华大学自动化系从事博士后研究。2011年起在清华大学自动化系任教至今。研究方向为视觉信息获取与重建,包括三维重建、运动捕捉、计算摄像等。已发表IEEE TPAMI、SIGGRAPH、CVPR、ICCV、ECCV等领域重要期刊及会议论文30篇。获2012年度国家技术发明一等奖(排名第三)、2008年度国家技术发明二等奖(排名第三),2013年度清华大学学术新人奖,2015年国家自然科学基金优秀青年基金。
报告题目:三维场景感知与理解
报告摘要:本报告主要讨论以下三个内容(1)三维视觉中的旋转不确定性,提出RIPN网络实现旋转不确定表征。(2)介绍细粒度的三维视觉表征,是三维数据之间的点级别(point-level)匹配(3)基于三维视觉和主动学习(active learning)我们推出了一个全新的机器臂抓取数据集GraspNet,可以在无需真实机械臂实验情况下,评价各种抓取算法。
嘉宾简介:卢策吾,上海交通大学研究员,博士生导师。2016年获得国家青年千人计划。2017年被评为科学中国人杰出青年科学家,2018年被《麻省理工科技评论》评为中国35位35岁以下科技精英,2019年获“求是杰出青年学者奖”(近三年唯一AI方向)。发表CVPR/ICCV/PAMI等顶会顶刊60多篇。发表的“Image smoothing via L 0 gradient minimization”在近7年的1000多篇TOG文章中被引次数最高,TOG被引用次数最高。担任国际AI学术顶会CVPR2020领域主席,国际会议CVM 2018大会程序主席。顶级期刊《nature》人工智能方向审稿人。
报告题目:三维视觉认知与学习
报告摘要:如何使以数据驱动的机器学习实现对不确定的复杂场景图像的准确认知迄今仍缺乏很好的理论支撑。本报告针对数据驱动的机器学习在不确定的复杂场景图像识别中的困难,引入认知心理学,提出了Thinking in 3D的思想,建模物体三维几何认知规律、挖掘图像客观属性。建立自顶向下的认知先验数学模型,并将其引入基于自底向上的数据驱动的机器学习中,提出了多模态、多视角、多任务三维场景图像深度学习认知方法(3DOP、Mono3D、MV3D,MOCF等),用于复杂驾驶场景中三维物体检测,发表在TPAMI、TIP、TITS、NIPS、CVPR上,在国际权威自动驾驶数据集KITTI上评测多次获得第一名。
嘉宾简介:马惠敏,北京科技大学计算机与通信学院教授,博士生导师,人工智能研究院副院长,物联网与电子工程系系主任,原清华大学电子工程系三维图像认知与仿真实验室负责人,现任中国图象图形学学会副理事长兼秘书长,北京市“三八红旗奖章”获得者。从事三维图像认知与仿真研究,作为负责人承担了国家自然科学基金、专项重点基金项目、国家重点研发计划子课题、国际国内企业合作项目20余项。近年作为通讯作者发表论文100余篇,包括PAMI、TIP、TITS、PR等高水平SCI期刊和CVPR、ICCV、NIPS等机器视觉顶级国际会议论文二十余篇,获得吴文俊人工智能科学技术创新奖一等奖,教育部技术发明奖二等奖、日内瓦国际发明展银奖。
报告题目:数据驱动的光度法三维建模
报告摘要:以多视角几何为代表的三维视觉方法可以通过一组图片恢复物体的三维模型,然而在特征点匹配不可靠的平滑区域,重建效果往往不尽如人意。以光度立体视觉为代表的光度三维建模方法可以通过输入固定视角下光源变化的一组图像,来获取精度更高的三维信息,表现为与主流二维图像分辨率等同(千万像素级别)的法线图。本报告介绍光度立体视觉的基本概念与最新进展。通过系统地对经典方法进行分类讲解,引入光度立体视觉的基准评测数据集,最后介绍近些年利用深度学习求解光度立体视觉的最新成果。
嘉宾简介:施柏鑫,北京大学计算机系数字媒体研究所研究员(“博雅青年学者”)、博士生导师,“相机智能”课题组负责人;北京邮电大学信息与通信工程学院兼职教授、博士生导师。于2007年、2010年、2013年从北京邮电大学、北京大学、日本东京大学获得工学学士、工学硕士、博士(信息科学与技术)学位。2013至2016年曾先后在麻省理工学院媒体实验室、新加坡科技设计大学、新加坡南洋理工大学从事博士后研究,2016至2017年曾在日本国立产业技术综合研究所人工智能研究中心任研究员。2017年入选中组部“千人计划”青年项目。发表国际期刊和会议论文70余篇(TPAMI、CVPR、ICCV、NeurIPS等),曾获2015年国际计算摄像学大会(ICCP)Best Paper Runner-Up,论文入选IJCV Special Issue: Best Papers from ICCV 2015。担任ACCV18、BMVC19、3DV19等国际会议领域主席,国际期刊IET Computer Vision副主编。更多信息请访问实验室主页:http://ci.idm.pku.edu.cn
报告题目:基于图像的大规模场景三维建模——从几何重建到语义矢量重建
报告摘要:自上世纪70年代计算机视觉成为一门独立的学科以来,在40多年的研究中,图像的三维表达,即从二维图像恢复场景三维结构始终是计算机视觉研究中的一个经典和基础问题。近年来,随着图像采集设备的不断进步,使用数码相机、街景车、无人机等设备可以方便的获取海量高分辨率图像数据,如何通过这些图像数据构建我们身边的三维世界日益成为许多领域的迫切需求。因此,在理论和应用层面,基于图像的三维重建这一经典问题都日益成为计算机视觉研究者的关注热点。本报告将介绍我们在基于图像的大规模场景三维建模方面的系统性研究工作,包括在稀疏重建、稠密重建、语义建模、矢量建模、视觉定位等领域的最新研究进展,以及在文化遗产数字化、智慧城市、高精地图、视觉重定位等多个领域的系统应用。
嘉宾简介:申抒含,中国科学院自动化研究所模式识别国家重点实验室副研究员,2010年于上海交通大学自动化系获博士学位。研究领域为三维计算机视觉理论与应用,包括基于图像的大规模场景三维重建、智能机器人三维环境感知、场景三维语义建模等。在IEEE Trans. on Image Processing、ISPRS Journal of Photogrammetry and Remote Sensing、Pattern Recognition、CVPR、ECCV、3DV等国际期刊和会议发表论文50余篇。所开发的图像三维重建算法集成于三维视觉开源系统TheiaSfM、OpenMVG、OpenMVS等。作为课题负责人主持和参与国家自然科学基金、973、863、中科院先导专项、以及各类企业课题十余项。入选中科院青促会会员、中科院自动化所特聘青年骨干,曾获2016年ACM北京新星奖,2018年中国图象图形学学会科学技术二等奖。
报告题目:多视几何SLAM与融入深度学习的SLAM
报告摘要:视觉SLAM在虚拟现实,增强现实,人机交互,无人驾驶,机器人导航等领域有着广泛的应用。本报告介绍视觉SLAM的最近工作进展,包括基于点到二次曲线几何距离捆绑调整的圆形marker SLAM,多特征融合的SLAM新框架,深度哈希相似分层的闭环检测,动态目标SLAM中的深度学习分割与运动模糊的抠图工作,大场景中深度哈希学习描述子与随机森林结合的视觉定位等。最后是对视觉SLAM的展望和趋势分析。
嘉宾简介:吴毅红,中国科学院自动化研究所、模式识别国家重点实验室机器人视觉组组长, 研究员,博士生导师。研究方向为多视几何理论、相机标定与定位、SLAM及在机器人定位与导航、AR、VR中的应用。在国际权威期刊和重要会议等上发表论文80余篇,包括PAMI、IJCV、ICCV、ECCV上第一作者论文。申请或获权国内外发明专利16项。曾担任ICCV、CVPR、ACCV、ICPR、IJCAI等的PC委员或Session/Area Chair。目前为《Pattern Recognition》编委、《自动化学报》编委、《计算机辅助设计与图形学学报》编委、《计算机科学与探索》编委,《Visual Computing for Industry, Biomedicine, and Art》编委。中国图象图形学学会三维视觉专委会副主任,中国图象图形学学会机器视觉专委会常委。首批阿里菜鸟驼峰计划特约专家。获三星电子校企合作卓越贡献奖。获1项高等学校科学研究自然科学奖二等奖。为诺基亚芬兰、三星、华为、百度等企业提供视觉SLAM技术服务累计10余年。
报告题目:Learning Correspondences for 3D Reconstruction and Pose Estimation
报告摘要:3D reconstruction and pose estimation are two fundamental problems in 3D computer vision. In most approaches to these problems, the foremost challenge is to establish correspondences between observations and 3D models. In this talk, I would like to discuss how to make use of learning-based methods to solve the correspondence problems in 3D reconstruction and pose estimation. To illustrate, I will introduce some of our recent works in this direction. The first is a transformation-invariant dense descriptor based on group CNNs with applications in SfM and visual localization. The second is a pixel-wise voting network for object pose estimation, which is robust to heavy occlusion and truncation. The final part includes a relative pose estimation method that can align RGBD scans with small or even no overlap via scene completion, as well as a learning-based pose synchronization method.
嘉宾简介:周晓巍,浙江大学计算机学院CAD&CG国家重点实验室“百人计划”研究员,国家青年千人计划入选者。2008年本科毕业于浙江大学,2013年博士毕业于香港科技大学。2014年至2017年在美国宾夕法尼亚大学GRASP机器人实验室从事博士后研究。研究方向主要是计算机视觉及其在增强现实和机器人等领域的应用,目前课题侧重于三维场景理解与重建,包括三维物体和人体的检测、识别、姿态估计、运动恢复、在线重建以及匹配等问题,近年来在计算机视觉与机器学习顶级期刊及会议(T-PAMI、CVPR、ICCV、NeurIPS、ICLR)上发表论文20余篇,并曾入围2019年CVPR best paper final list。策划和组织了Geometry Meets Deep Learning Workshops,并长期担任PAMI、IJCV、TIP等二十余种SCI期刊审稿人以及CVPR、ICCV、IJCAI等计算机领域顶级会程序委员会委员。详情请见个人主页:http://www.cad.zju.edu.cn/home/xzhou
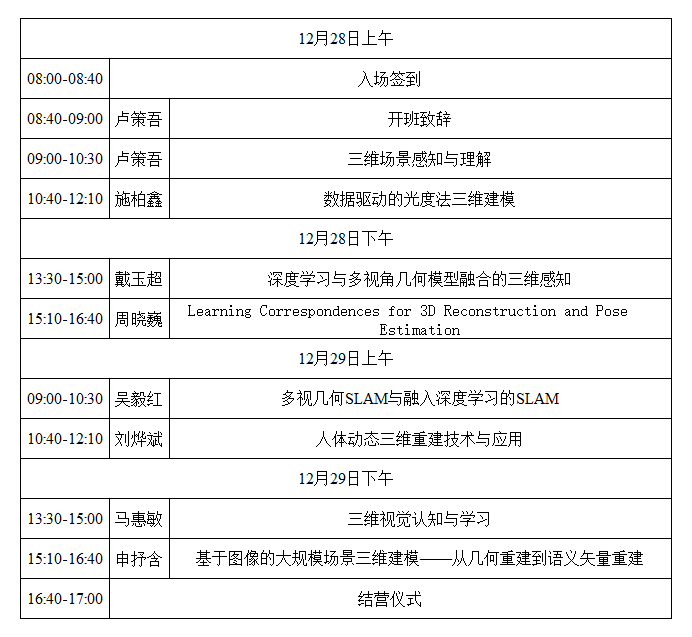
五.活动日程
六.注意事项
1、本期讲习班限报200人,根据缴费先后顺序录取,报满为止。
2、2019年12月27日(含)前注册并缴费:CSIG会员1600元/人,非会员报名同时加入CSIG 2000元/人(含1年会员费);同一单位组团(5人及以上)报名,均按CSIG会员标准缴费;CSIG团体会员参加,按CSIG会员标准缴费;现场注册:会员、非会员均为3000元/人。
3、注册费包括讲课资料和2天会议期间午餐,其它食宿、交通自理。














