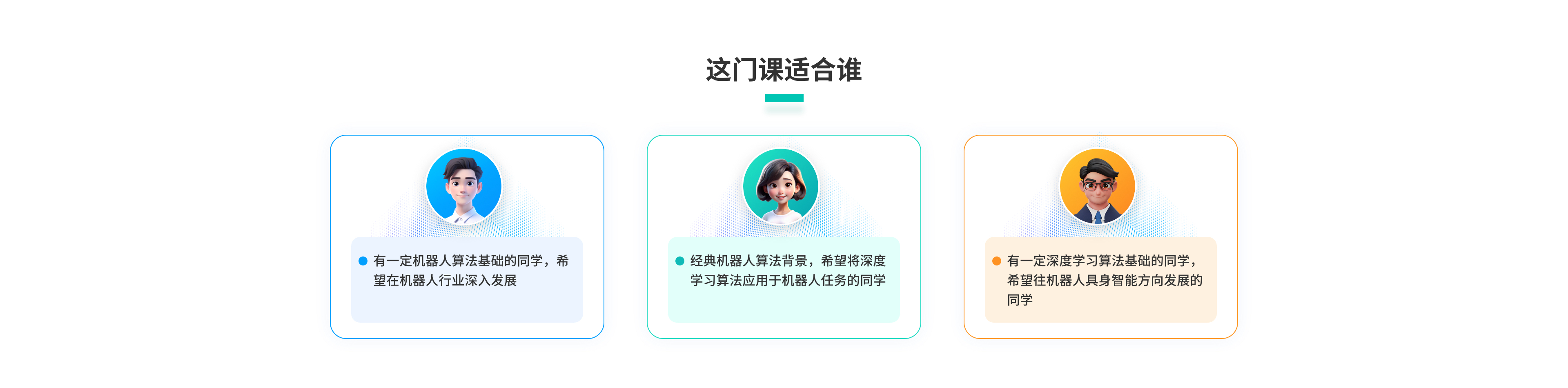
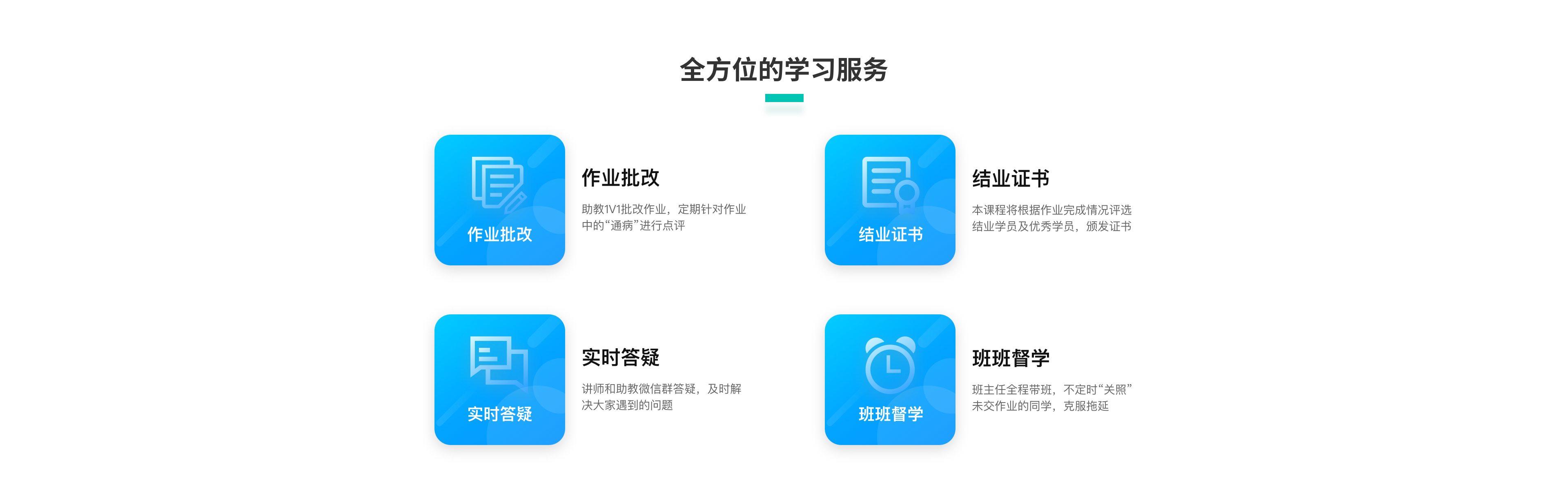
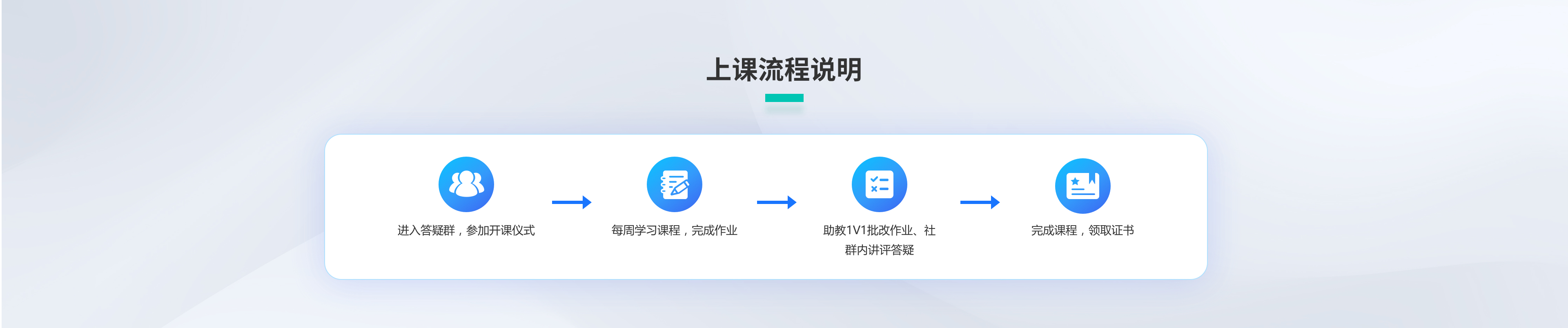
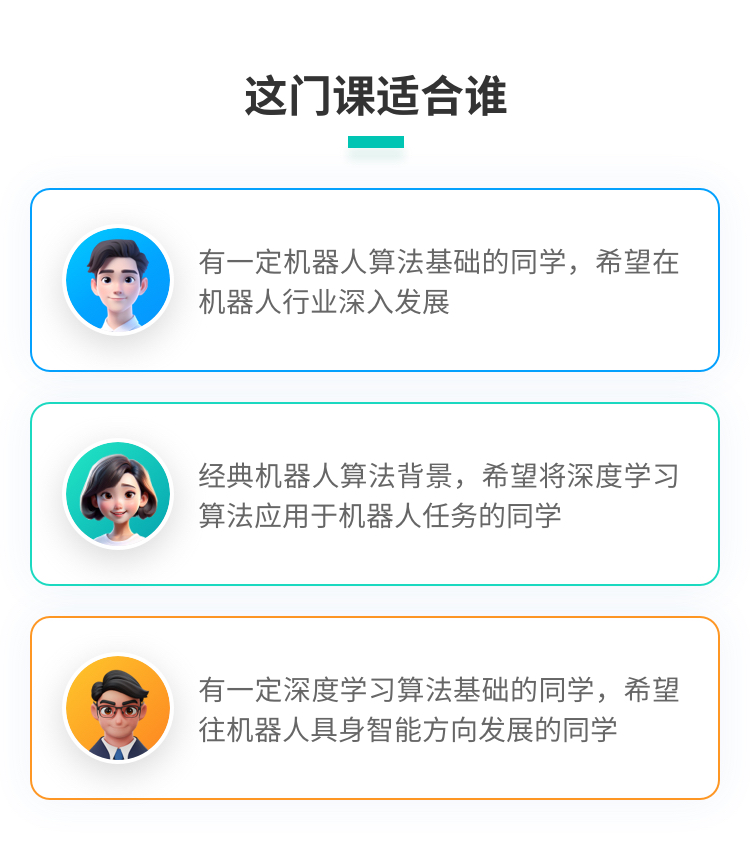
课程价格 :
¥899.00
剩余名额
0
-

学习时长
10周/建议每周至少6小时
-

答疑服务
专属微信答疑群/讲师助教均参与
-

作业批改
每章节设计作业/助教及时批改评优
-

课程有效期
一年/告别拖延,温故知新










- 1-1:开班典礼
- 1-2:【资料】推荐论文合集
- 第1章: 机器人抓取与操作介绍
- 2:【课件】机器人抓取与操作介绍
- 第1节: 课程介绍
- 免费 3:【视频】课程大纲和介绍
- 第2节: 机器人运动规划控制方法介绍
- 免费 4:【视频】机器人运动规划控制方法介绍
- 第3节: 机器人传感器和视觉介绍
- 免费 5:【视频】机器人传感器和视觉介绍
- 第4节: 机器人学习方法介绍
- 免费 6:【视频】机器人学习方法介绍
- 第5节: 实践工具
- 免费 7:【视频】实践工具与总结
- 第6节: 本章作业
- 8-1:作业说明文档
- 8-2:【作业】Project1:使用 ACT 在 MuJoCo 中训练机械臂完成抓取任务
- 8-3:作业代码文件
- 第2章: 经典规划控制方法
- 第1节: 规划算法
- 9:【课件】 经典的规划方法
- 10:【视频】规划算法
- 11:【视频】基于树结构的方法
- 12:【视频】基于图结构的方法
- 13:【视频】规划算法的扩展
- 14:【视频】轨迹生成
- 15:【视频】轨迹优化,插值,样条曲线
- 第2节: 控制算法
- 16:【课件】 控制算法介绍
- 17:【视频】控制算法简介
- 第3节: 抓取方法
- 18:【课件】操作与抓取算法
- 19:【视频】操作与抓取的传统方法
- 第4节: 使用案例
- 20:【课件】机器人应用案例
- 21:【视频】机器人实用案例讨论
- 第5节: 本章作业
- 22-1:作业说明文档
- 22-2:【作业】Project2:基于RRT算法的机械臂路径规划
- 22-3:作业代码文件
- 第3章: 机器人视觉方法
- 第1节: 传感器和标定介绍
- 23:【课件】L3-1机器人视觉方法
- 24:【视频】传感器
- 第2节: 视觉图像和神经网络+3D感知和点云处理
- 25:【课件】L3-2神经网络,2D和3D图像处理
- 26:【视频】神经网络,2D和3D图像处理
- 第3节: 3D位姿估计-机器人场景
- 27:【视频】位姿估计
- 28:【课件】L3 sec3 位姿估计.pdf
- 第4节: 本章作业
- 29-1:作业说明文档
- 29-2:【作业】Project3:PoseCNN 6D姿态估计与抓取
- 29-3:Project3.zip
- 第4章: 基于深度学习的抓取
- 第1节: 2D平面抓取
- 30:【课件】L4 sec1 2D Grasping.pdf
- 31:【视频】抓取问题介绍与2D平面抓取方法
- 第2节: 6DoF Grasping
- 32:【课件】L4 sec2 6DoF Grasping
- 33:【视频】6DoF Grasping
- 第3节: Other Applications
- 34:【课件】L4-3Other Applications
- 35:【视频】Other Application
- 第4节: 本章作业
- 36-1:作业说明文件
- 36-2:【作业】Project4:基于GR-ConvNet的物体检测与机械臂抓取
- 36-3:project 4.zip
- 第5章: 模仿学习
- 第1节: Intro and BC
- 37-1:【视频】Intro and BC
- 37-2:【课件】Intro and BC
- 第2节: Interactive IL
- 38-1:【视频】interactive IL
- 38-2:【课件】interactive IL
- 第3节: Inverse RL
- 39-1:【视频】Inverse RL
- 39-2:【课件】L5 sec3-4-5 inverse RL and generative IL.pdf
- 第4节: IL with Sequence Information
- 40:【视频】IL with Sequence Information
- 第5节: Generative model for IL
- 41-1:【视频】生成式模仿学习的思想
- 41-2:【视频】GAIL与VAE的方法
- 41-3:【视频】Diffusion Policy
- 第6节: 本章作业
- 42-1:作业说明文件
- 42-2:【作业】Project5:基于Diffusion Policy的物体检测与机械臂抓取
- 42-3:作业代码文件
- 第6章: 强化学习方法
- 43:【课件】第六章
- 第1节: 强化学习简介
- 44:【视频】强化学习简介
- 第2节: Q learning
- 45:【视频】Q-learning
- 第3节: Policy Learning
- 46:【视频】Policy Learning
- 第4节: Actor-Critic
- 47:【视频】 Actor-Critic
- 第5节: Offline RL and Inverse RL
- 48:【视频】inverse and offline RL
- 第6节: Other Methods and Discussions
- 49:【视频】others
- 第7节: 本章作业
- 50-1:作业说明文档
- 50-2:Project6:基于强化学习的机械臂逆运动学解算与抓取
- 50-3:作业代码
- 第7章: 具身智能:VLM与VLA模型(3次课)
- 第1节: Introduction
- 51:【视频】章节介绍
- 第2节: Transformers and Generative Model
- 52:【课件】Transformers and Generative Model
- 53:【视频】Transformer与生成式模型
- 第3节: ACT & Variants, Diffusion Policy
- 54-1:【课件】L7 sec3 ACT & Variant, Diffusion Policy
- 54-2:【视频】ACT & Variant
- 54-3:【视频】Diffusion Policy
- 第4节: VLM&LLM for Planning
- 55-1:【课件】LLM&VLM for planning
- 55-2:【视频】LLM&VLM for planning
- 第5节: VLA: RT1, RT2, Octo and OpenVLA
- 56:【课件】VLA:RT系列、Octo与OpenVLA
- 57-1:【视频】什么是VLA
- 57-2:【视频】VLA的背景与介绍
- 57-3:【视频】VLA算法之RT-1
- 57-4:【视频】VLA算法之RT-2与其它RT系列
- 58-1:【视频】VLA算法之Octo
- 58-2:【视频】VLA算法之OpenVLA
- 58-3:【视频】小结
- 第6节: VLA: RDT, Pi0 and Others
- 59-1:【课件】VLA:RDT, Pi0 and Others
- 59-2:【视频】本小节内容引入
- 59-3:【视频】RDT算法
- 59-4:【视频】Pi0算法
- 59-5:【视频】VLA总结
- 第7节: Dataset and Benchmark
- 60:【课件】L7 sec7 Dataset
- 61:【视频】Dataset
- 第8节: Others & Summary
- 62:【视频】Summary
- 第9节: 本章作业
- 63-1:作业说明文档
- 63-2:Project7:GR00T N1在 Libero 数据上微调对比
- 63-3:作业文件
- 第8章: 工程经验和总结展望
- 64:【课件】总结与展望
- 第1节: 总结&展望
- 65:【视频】Summary
- 第9章: 直播答疑汇总
- 66:【直播回放】直播答疑交流06期12.29