








-

开课时间
2025.08.28 20:00
-

课程时长
83分钟
-

学习人数
11273人次学习
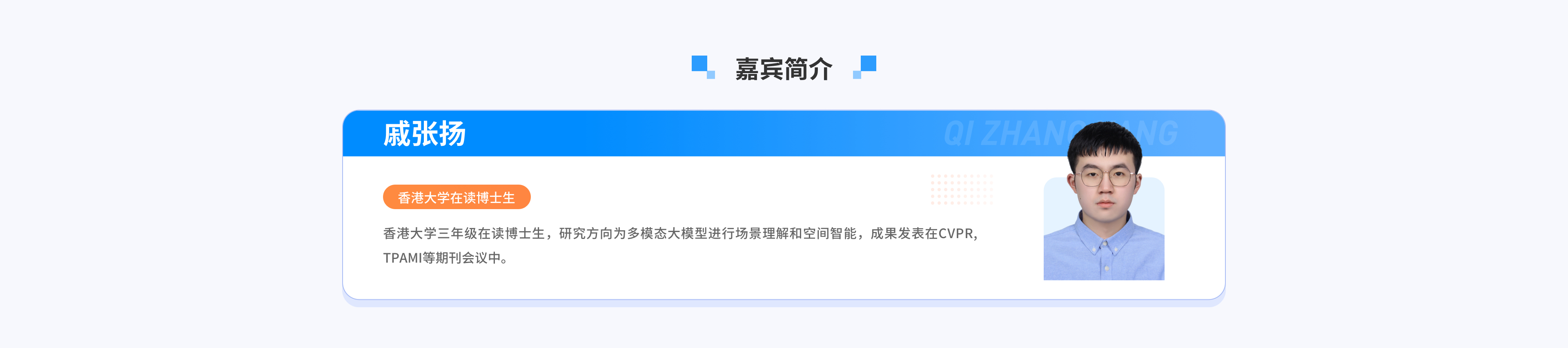
添加助教,入群交流,领取课件
- 课程介绍
- 课件领取
- 相关课程










2025.08.28 20:00
83分钟
11273人次学习




 报名成功
报名成功

















