-
策略梯度中参数更新问题
——来自《强化学习理论与实践- 第一期》·32浏览
@橘朵 指的是概率值。利用pi这个网络求出,对应st,at处的概率值。
-
策略梯度中参数更新问题
——来自《强化学习理论与实践- 第一期》·32浏览
同学你好:
这个是Actor的损失函数。根据策略梯度定理,我们知道,Actor的更新过程是参数加上
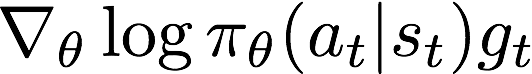 ,因此我们可以认为策略梯度的目标就是最大化
,因此我们可以认为策略梯度的目标就是最大化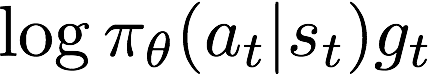 ,即最小化
,即最小化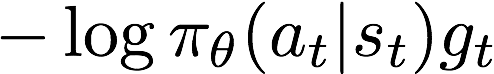 。
。所以我们认为其loss函数为
。这个损失函数由两部分组成,一部分是策略pi在at,st处的概率的负对数,另一部分是gt(也可以替换成优势函数,值函数等)。注:1,你贴的代码中one_hot是为了挑选出at的概率,比如动作空间是{A, B, C},一共有三个动作,那么pi会输出三个概率。假设at=B,那么one_hot那一句代码就是为了挑选出pi在B处的输出概率。
-
策略梯度中参数更新问题
——来自《强化学习理论与实践- 第一期》·32浏览
@橘朵 你对one-hot的理解出了偏差。
one-hot不是对角矩阵哦。你可以尝试以下代码测试一下:
>>>> act = tf.constant([1], dtype=tf.int32) # 动作B
>>>> one_hot_act = tf.one_hot(act, 2) # 2表示动作空间的大小
>>>> sess.run(one_hot_act)
-
关于资格迹的实现问题
——来自《强化学习理论与实践- 第一期》·29浏览
同学你好:
我怎么感觉你好像忘记乘gamma了。
-
关于资格迹的实现问题
——来自《强化学习理论与实践- 第一期》·29浏览
同学你好:
哦哦,抱歉,我一开始没理解对你的意思,原来你指的是一条轨迹出现两个相同的状态。
这个确实是这样的,我在视频中应该也强掉了这个公式只是考虑一个状态的作用,如果真正考虑一条轨迹的话,应该是轨迹中的每一个位置的状态都能求相应的资格迹,然后合并。
-
关于资格迹的实现问题
——来自《强化学习理论与实践- 第一期》·29浏览
同学你好:
你可以仔细回顾,我在TD(lambda)那一节有个小结,后向视角只有TD(0)等价于前向视角的TD(0),其他的lambda下,并不会完全等价。你这个实现完全是正常的哈。
-
第八课 打砖块作业中的问题
——来自《强化学习理论与实践- 第一期》·13浏览
同学你好:
1. 首先,80次指的是episode数量?还是step的数量?
2. 具体是什么问题需要自己debug,才能查出来:
2a. 首先你可以通过视频显示,来观察具体做了什么动作
2b, 在真正训练一个环境前,首先应该做的就是使用一个随机动作的agent测试一下。不仅仅是为了测试实验环境的准确性,还可以作为对比的baseline。
-
同学你好:
确实会影响策略梯度的值。但是你要理解前面t-1项与action无关,那么期望的情况下,前面t-1项的值与梯度的项相乘应该为0。
我举一个例子:
比如你考试好不好只跟你的学习过程有关系,跟你吃不吃饭没关系,我们在计算完整轨迹的时候会包含吃饭,但是在期望的情况下,吃饭的结果对参数的导数应该是0,即在大量采样的情况下,两者统计独立。
因此这里删除t-1项会影响策略梯度,但是在大量的轨迹情况下会相互抵消。
既然我们知道一个东西跟参数的关系是0,与其通过实验采样出+1,+2, -2, -1,然后通过加权求和抵消,不如直接设为0,方差会小很多。
-
同学你好:
其实两者都可以。都属于部分观测的。
对于这个问题来说,两个灰色区域明显是不同的,如果能看到整个地图导致能够明显区分,那么就是全观测的。对于这个问题,只要是因为观测问题,导致无法知道自己处于什么位置,都可以认为是部分观测。
-
同学你好,
我的理解是,TD(lambda)也要求Markov性。根据资格迹的计算,每次统计到s就对s的资格迹+1,这里的一个关键点是,我们只关注是否统计到了s,而没有考虑agent是怎么到达s的。这也是Markov性的体现。
-
蒙特卡洛作业起始终止位置设定。
——来自《强化学习理论与实践- 第一期》·20浏览
同学你好:
欢迎参考回答 http://www.shenlanxueyuan.com/course/96/thread/100
-
关于n步重要性采样问题
——来自《强化学习理论与实践- 第一期》·30浏览
同学你好:
其实两者都是对的,是通过两种不同的重要性采样方法导出来的。我课件的那种叫Ordinary importance sample, 而书上的那种叫做Weighted Importance Sample。
-
关于n步重要性采样问题
——来自《强化学习理论与实践- 第一期》·30浏览
@linjianbing 实际使用的话,最好用书上那种,方差更小些,更稳定。
-
关于重要性采样对方差的影响
——来自《强化学习理论与实践- 第一期》·21浏览
同学你好:
你可以参考书的114-115页,Example5.5。举了一个无穷大的方差的例子。
-
第四节课编程作业一些提问
——来自《强化学习理论与实践- 第一期》·24浏览
同学你好:
在没有限定初始位置的情况下,最好是随机选择初始位置。在这个问题中,选择别的初始位置,导致(2,4)处的策略不正确是有可能的。初始状态是会影响到其他状态的探索次数的,即便你使用了带epsilon的探索策略。
-
关于第四节作业的问题
——来自《强化学习理论与实践- 第一期》·37浏览
同学你好:
我不太明白你说的片段数是什么意思?我理解的是指轨迹的长度T,如果是T的话,不用太长,因为0.9的50次方就很小了。
不过轨迹的数量越多越好,因为相当于重复实验的次数增多,会大大减少估计的方差,从而接近真实值。
-
关于第四节作业的问题
——来自《强化学习理论与实践- 第一期》·37浏览
@Albert 一个episode指的是一条轨迹,也可以称为一个片段。轨迹的长度应该用episode length
-
关于第四节作业的问题
——来自《强化学习理论与实践- 第一期》·37浏览
@Albert 有差是正常的,虽然到一定长度之后的权值很小了,但是架不住这是一个无穷时间的问题。积少成多嘛,所以还是有差距的
-
关于第四节作业的问题
——来自《强化学习理论与实践- 第一期》·37浏览
@Albert 其实作业的目的,也就是让大家体会MC虽然简单,确实对数据的要求比较大
-
关于教材上离策略例子的问题
——来自《强化学习理论与实践- 第一期》·26浏览
同学你好:
重要性采样,会对采样值计算一个重要性采样率,不过如果乘了采样率,在batch方法中可能导致加权求和不为1.
所以我们需要搞一个加权方法。这里是两种加权手段。
其实我们off-policy的MC用的比较少,所以课堂上这一点没提。
具体应用off-policy最多的时候,就是Q学习了。我们的target policy是贪婪的,但是会用一个epsilon贪婪的策略去探索。这一点可以在TD算法的那一节学到















