-
学习讨论总结_第八章
——来自《语音识别:从入门到精通- 第一期》·97浏览
kaldi理解WFST,HCLG,lattice:
https://blog.csdn.net/qq_36782366/article/details/102847110
Q1 建模思想
问:Forward算法和viterbi算法有什么联系?
答:在相邻的t-1到t时刻,forward做的事情是把所有可能的状态做sum,而Viterbi是找到最大的一条路径。
问:argmaxP(O|W)P(W)直接应用有什么问题?
答:P(O|W)粒度小(HMM,状态级别,概率不都接近于1),P(W)粒度大(word级别,概率接近于1)。解决:加入language model weight和word insertion penalty。
问:LMWT和WIP^N它们的具体的值是经验得出的值还是还是根据语料库学习出来的?如果是后者,那么在kaldi中那个地方可以查看到?
答:LMWT一般是7到17之前,不同语料不同数据集合不同;WIP一般0,0.5,1中的一个。会在dev集合上遍历,然后选一个适合数据级的LMWT和WIP。看local/score.sh
问:openfst中的状态有什么含义?和HMM的状态有联系吗?
答:和你学的HMM状态没有任何对应关系。通常它的意义比较隐式,或者没什么意义,你理解为每个时刻要停留在一个状态上就好。在G进行确定化最小化之前,上面的状态表示,可以比较明显推理出是某个history。随着确定化和最小化,就越来越难理解了。
Acceptor是判断一个input序列是否可以接受,Transducer是判断一个string是否可以转化成另一个string,所以信息主要集中在arc上。主要看有没有一条从初始状态到结束状态的完整路径(我觉得大家会想,所以我在讲G的时候说了一下,但是后面这个意义越来越隐式模糊了)。
问:解码的过程就是compose的过程是吗?如果compose的时候,路经能走通就是合理的结果,走不通就舍弃,最后把hclg都compos之后就得到解码结果,解码结果是多个,有best path,还有lattice是这样吗?
答:解码过程可以理解为compose过程。这段理解可以,你可以把所有合理结果存成lattice形式,最好的合理结果就是best path。
问:训练时用到的L.fst看着没啥作用啊,难道只是为了编程方便?而且训练时的l.fst和组成hclg的那个l.fst好像不同?
答:L.fst是phone sequence到word的映射,没有你怎么结合每个音素的hmm,怎么结合LM。看一下HCLG最后面总结的ppt,每一部分都是层层递进的。主要区别在于消歧义符,训练你知道抄本,所以你能准确找到对应的音素序列;但是解码你不知道某个词的发音是否为另一个词的前缀,或者同音字。例如,word1 phone1, word2 phone1 phone2,当你解出来phone1时候,你不知道是找到了word1,还是没找全的word2,所以加消歧义符号来处理这种事情。Q2 剪枝
问:beam pruning 和 histogram pruning 有前后关系吗?
答:通常beam pruning是在你每一帧里逐个处理token时候用的,histogram pruning是这一帧处理完成了进行,作为下一帧的开始。当然,也可能是这帧epsilon都处理完,准备开始处理non-epsilon时候用。我觉得比较好说beam pruning是随着token产生进行处理,histogram是操作collect的一个token set
Q3 解码图
问:pdf-id是什么?pdf-id和transition-id之间的对应关系是什么样的?
答:pdf-id是GMM的概率分布,也就是HMM的发射概率。pdf-id到transition-id是一对多,但是transition-id到pdf-id是一对一。
问:lattice和compact lattice如何转换?
答:lattice-copy的参数 --write-compact=true of false
问:compactLattice 是 acceptor,将 transIDs 放在 weight 上。lattice 是 FST,transID 放在 ilabel 上,<eps> 作为 olabel 是表示什么也不输出吗?
答:epsilon在ilabel和olabel都可能出现,输入就是不需要输入的跳转,输出就是空,一个word总要对应很多transition-id,所以很多olabel都是空。
问:建立CLG时,决策树有没有被compose进去?
答:有的。构建C的时候会需要你三音素的位置信息(宽度和中心音素位置),构建H的时候需要tree,帮你决定pdf(每个状态的发射概率密度函数)和cd-phone的对应关系。解码的时候不需要再查询决策树了。
问:输出phone有什么意义?
答:H是输入transition-id输出cd-phone-id,C是输入cd-phone-id输出phone-id,L是输入phone-id输出word-id,G是输入输出word-id。为了能进行C和L的compose,你需要让C的olabel是合理的phone-id。具体输出中心phone-id还是右边phone-id,只是不同工具的作者不同的选择
Q4 wfst应用
问:wfst的start state是否一定只有一个?Process nonemitting之后变成了多个是怎么回事?
答:start state有一个这个问题只能现定于openfst,并且它的start state没有weight。但是在自动机理论里,start state可以是一个状态集合,也可以有权重lamda。这只是具体实现问题,你就认为是一个就可以。processnonemitting就是处理ilabel=epsilon的情况。
问:构建好HCLG.fst后,解码时用的应该也是token passing算法吧?
答:是的
问:解码过程中声学模型final.mdl, pdf-id序列,HCLG解码图之间是如何交互的?
答:直接在HCLG上运行跳转。所有LM,转移概率都在HCLG的weight上,而每个arc的input是transition-id可以找到对应的pdf-id。
粗略的说:一帧数据来了,HCLG上要从一个状态跳转到另一个状态,他们之间有一个arc,从input label的transition-id找到对应的pdf-id,你就能算出来acoustic score, 然后arc上的weight就是graph score(相当于LM score,多音字概率,转移概率等)。这就相当于你HMM发生了一次跳转。
问:(接上问)acoustic score,是把这一帧数据输入网络,拿到该pdf-id对应的那个网络输出节点的输出值就是acoustic score吗?
答:神经网络的输出是posterior,通常你要减去prior,然后拿到pdf-id对应的输出结点的值才是acoustic score。
问:wfst 为什么是消耗第一个输入就输出 word,后面输出 eps。而不是前面输出 eps,消耗完所有输入再输出 word?
答:这个其实在基本decoder是没有区别的,因为确定化后,一个输入对应的输出是唯一的。但是对于以前的非WFST解码器或者你看到的WFST解码器,它都倾向于越早输出词越好。这样非WFST解码器或者需要online rescore的wfst解码器、A*解码器等可以让你更早的用到LM的weight,而尽早剪枝。
问:当构建好了wfst图,识别的时候,在某一时刻(此时应该已经有很多token了),来了一个新帧。识别的步骤是不是,首先由已有的token推测接下来所有可能到达的状态,然后再计算这么多条路径每一条的概率?
答:每个token,对应wfst图里的一个状态。
你用一个queue,逐个处理每一个token,就相当于遍历处理wfst对应的那个状态的所有出去的arcs。
问:您提到的重解码的意义在哪里,离散已经有了更好的语言模型,为什么不直接用这个语言模型compose?
答:构图的wfst会很大,解码很消耗内存,你用2gram可能wfst有几G,用4gram可能几十甚至上百G。所以搜索速度和内存都是问题,通常会选一个小的LM一遍解码,然后rescore。
问:已经生成了hclg,那么怎么进行重解码呢?这里面不是已经有了一个语言模型么,也就是说目前不存在的路径,但可能存在于更好的lm中的路径已经被删掉了,有个新的语言模型还有什么用么?
答:rescore是在lattice上面,你会把graph的分数和acoustic的分数分开存,替换分数。如果最终的路径已经被裁掉了,rescore是不能恢复的,你通常可以用比较松的剪枝策略,生成较大lattice,减少裁掉ground truth的概率。
问:训练语料中从未出现过,但是词典中有的词,在测试集可以解码出来吗?如果能解码出来,是怎么来的呢?
答:因为G中存在,你在做语言模型的时候用的也是这个字典,会因为打折算法给这些unseen event一个概率。字典中有这个word,自然L.fst中有它和音素的映射关系。
问:src/decoder/lattice-faster-decoder.cc 用到了weight,cost和likelihood,他们之间有什么区别和联系呢?
答:WFST上面的weight就是LM概率,transition概率等的组合,存在图上的时候是-ln域。
likelihood是贝叶斯公式里的通常叫法,还有先验prior,后验posterior。把特征帧带入GMM获得的是likelihood,把特征带入NN获得的是posterior,然后转化为likelihood给解码使用。通常是ln域的。用作cost时候取负数即可。
cost,顾名思义,就是花费代价,越大越差。-ln域的值就是这个特点,值越大,概率越低。
Q5 作业
问:getcutoff()的输出比较困惑。感觉剪枝后的是tokens数目,看代码只是用max_active/min_active/beam三个数进行了约束(取其中小的那个值?),视频里讲beam是控制beam pruning ,max_active是控制histogram pruning的,这里面是怎么实现的呢?
答:首先,你要明确,每个token都属于某一帧,并且都有一个state_id(显然,同一帧没有相同的state_id),这个state_id就对应了WFST里面的state编号。
然后,你要知道,处理某个token,就是根据token的state_id,在wfst上对应state上遍历所有arcs。arcs有两种,input label为epsilon和non-epsilon。其中epsilon是不消耗feature的,由ProcessNonemitting处理;non-epsilon是消耗feature frame的,由ProcessEmitting()处理。
Decode()最开始和会调用InitDecoding(),里面用了ProcessNonemitting()来处理。之后对于每一帧依次用ProcessEmitting和ProcessNonemitting处理。lattice-faster-decoder里面会将每一帧的token存放在active_toks_[i](active_toks_里面每一帧是一个链表),但是处理某一帧为了快速,有一个HashList toks_。【这些细节有兴趣自己可以看看】。输入实际上就是上一帧处理后的所有tokens,你可以理解为trellis里面的一列(e.g. t-1列)。然后ProcessEmitting开始处理,调用getcutoff(),其中max_active(你可以暂时忽略min_active,他是防止当前帧token太少,lattice多样性太小)是histogram pruning,beam是beam pruning,共同作用,取小的,留下比较可靠的tokens (e.g. 比如beam限制后留下了9k个,然后max_active是7k,你最后留下前7k)。这里就是对当前帧的token,根据tot_cost排序,然后根据beam和max_active获取前N个好的token,即cur_cutoff这个界限。(用cutoff和直接删除token是一个意思,tokens还在链表和Hashlist的结构中,删除麻烦且耗时!所以用cur_cutoff阈值,当正式处理时跳过超阈值的token)【我想代码还是你们一行行看比较好,我给你讲每一行,有点不现实】。你可以获得当前best_token,然后根据它向前传递依次,估计一个next_cutoff,来对trellis下一列(e.g. t列)进行beam剪枝。之后你逐个处理tokens,在ProcessEmitting()处理non-epsilon的arcs,输出就是trellis里面第t列。然后ProcessNonemitting(BaseFloat cutoff)处理epsilon的arcs,输入自然是目前trellis的第t列,这里用了一个queue,因为epsilon的arc处理后的token还在同一列,需要继续。这里也用cutoff实现着beam pruning,(1)比较tot_cost和cutoff判断是否处理该token;(2)处理epsilon arc之后,即加graph_cost之后是否有希望,然后FindOrAddToken()尝试进行Token Merging(注:每个state只保留一个token)。这样处理直到完成。所以输出是帧处理后剩下的所有tokens。也作为了一下次的输入。问:GetCutoff得到infinity是否有问题?
答:对于第一帧GetCutoff得到infinity是正常的,一般min_active_tokens会设置一个比较小的数值,比如20。如果你原本这一帧初始的准备处理的tokens比这个min_active还要小,就会返回infinity。
比如你的min_active=20,你这帧最开始只有10个tokens,那么这10个tokens都会被处理,这个cutoff=infinity -
学习讨论总结_第七章
——来自《语音识别:从入门到精通- 第一期》·100浏览
Srilm工具包介绍
http://www.52nlp.cn/language-model-training-tools-srilm-details#more-954
Srilm安装说明
注意改目录的时候不要在最后加空格,否则make会报错 xxx is a directory. stop
Macos:https://blog.csdn.net/codia1/article/details/62044674
Ubuntu: https://note.youdao.com/ynoteshare1/index.html?id=60bd2b1cbdc67b64ca6b722675399131&type=note
Q1 词典
问:没出现过的词怎么处理?
答:统一处理成<unk>
Q2 调整计数
问:调整计数的“分母不变,只变分子”怎么理解?
答:add-one举的例子,用add-one smoothing之前是P(wi)= C(wi) / N;用了之后是P(wi) = C(wi) + 1/ (N+V)。分子分母都变了。调整计数时候说分母不变,只变分子,这样可以比较好的和原来比较。所以你可以把平滑后表示成 P(wi) = 分子[(C(wi) + 1) * N / (N+V)] / 分母[N]。这样你比较前后,相当于计数从C(wi)变成了(C(wi) + 1) * N / (N+V),直观看出来打折多少。
问:对于tri-gram,有些词w1w2的组合出现次数可能是0,那求打折率的时候不是打折计数除零了嘛?还是该怎么算?
答:你是P(w3|w1w2),如果w1w2都不存在,w1w2w3也肯定不存在,对这个没有打折的说法了,不存在除零。不论回退还是插值,你都用低阶LM表示了。
问:katz建议的调整计数算法是归一化的吗?
答:是的
问:绝对折扣算法中,回退到一元模型的归一化参数为什么是alpha(wi)而不是alpha(wi-1)?
答:本质上这只是一个记号,alpha就是用来归一化的,你需要理解,它保证最后是概率,sum_wi[ P_absolute(wi|w_{i-1}) ] = 1,就可以了。
对于katz平滑,你可以看ppt21页,算系数的时候,相当于把wi加掉(换句话说你把平滑后的N阶概率加一起就可以了),如果你记成了alpha(w_{i-N+1}到w_i),认为算系数时候w_i限制了大于0,我更喜欢。尊重原文我保留了这种记法。这里absolute算法也是类似,当然写成alpha(w_{i-1})可能更统一。
Q3 插值和回退
问:插值法的参数如何确定?
答:可以用经验值,也可以在hold-out set上用MLE
Q4 语言模型存储
问:为什么最高阶语法和</s>结尾的任意阶语法没有回退权重?
答:因为APRA format只保存非零的N元语法概率。</s>因为是结尾,不可能成为其他词的历史。
问:为什么插值模型和回退模型都可以如此储存?
答:标准存法是回退式,如果存插值只要把打折后的概率改成插值后的结果即可。
Q5 RNN语言模型
问:RNN语言模型相对传统语言模型有什么优缺点?
答:RNNLM其实我最想让你们感觉到的是:因为RNN模型本身固有的性质,理论上使得它可以浑然天成的建模从起始开始到当前的所有history。讲的那个output词袋我曾经参与kaldi的rnnlm时候非常有用的一个策略,所以我讲了。当然RNNLM还有很多可以优化的技巧,比如训练数据的采样的技巧(可以看看Kaldi的LM),或者RNN模型本身的优化,或者"Training Neural Network Language Models on Very Large Corpora"等论文里面提到的优化技巧,或者根据任务做一些adaptation,但是我觉得这都是技巧,当你要用的时候需要找些论文多多学学。我最想让你知道的是RNN为什么可以建模语言模型,它比普通的FeedforwardNN只能靠增加输入的维度,要更自然。
问:RNNLM如何与WFST结合?
答:此外RNNLM确实比较难合并到WFST,它是要做类n-gram的处理,用到一些技巧,kaldi里你可以看到OnDemandFst,如果感兴趣的话可以看一下。但是RNNLM用起来还是很慢的,据我了解,很难在一遍解码上实时,对于单句来说。
Q6 其他语言模型
问:Cache model是不是只适用于连续对话,不太适用于单条音频?
答:Cache model是需要一些上下文的对话,如果独立的单条效果应该不是很好。并且cache model训练的时候为了这个上下文,也会做一定的拼接,放到一个batch里面,从而保证上下文足够多,信息比较充分。Cache model我做的的比较少,jhu的时候组里有人做,当时她在swbd(电话对话)上能获得大概5%的wer相对提升。
Q7 作业
问:为什么会出现error in discount estimator for order 3错误?
答:正常你只用把数据放到一个文件里,做好分词就更简单了,而不用-read。当然两者都可以。例如:
ngram-count -text /home/Ch7/lm/train -order 3 -limit-vocab -vocab /home/Ch7/lm/wordlist -unk -map-unk "<UNK>" -ukndiscount -interpolate -lm ./a
出现问题,加上'-debug N'来调试,你会发现问题。
-kndiscount是modifying的KN算法,由goodman他们提出的,-ukndiscount是原始的。他们会统计出现过N词的n-gram计数,就是good-turing里面那个计数。对于原始版本,会统计n1,n2然后D= n1/(n1 + 2n2);对于modifying版本,会统计n1,n2,n3,n4。Y=n1/(n1 + 2n2), D1=1-2*Y*n2/n1, D2=2-3*Y*n3/n2, D3plus = 3-4*Y*n4/n3。
有的时候数据集太小,或者人为写的,通常会发现对于高阶N-gram出现没有n_x统计计数。这时候常换为witten bell。
问:第7章作业指导书里说两种count(of the)大部分情况都一样,那什么情况下会不一样呢?
答:发生在句子开头<s>和结尾</s>。举个例子,比如你要对一个句子做3-gram,你会把句子扩展成"<s> <s> I am a man </s>"。你如果count_history的话是"<s> <s>", "<s> I", "I am", "am a"和"a man"加一; 如果统计bigram的count的话是"<s> I",“I am", "am a", "a man"和"man </s>"加一。所以计数不同。
【对于thchs30】
训练集中的每条句子都至少重复 7 次,例如:“他 代表 俄语 学院 向 奈 娜 夫人 赠送 了 一 套 与 普希金 俄语 学院 合编 的 教材 东方 俄语”导致 1gram,2gram 和 3gram,甚至 21gram(长度不足 21gram 的不算),出现次数最少的都不低于 7 次,即 n1=n2=n3=n4=0
-
学习讨论总结_第六章
——来自《语音识别:从入门到精通- 第一期》·45浏览
Q1 HMM-DNN和HMM-GMM的关系
问:GMM-HMM训练中会基于Viterbi算法的强制对齐方法给每个语音帧打上一个HMM状态标签,DNN-HMM在这个状态标签的基础上进行训练。我们知道这样给出的标签是不准确的,那为什么能够参考一个不太准确的状态标签,训练出一个更准确的状态标签出来,这其中的原理是什么呢?
答:对齐出来的标签基本是准确的,或者说有比较高的准确率。DNN同GMM方法相比,两者的特征和标签(对齐)是一样的,只是模型不一样。
问: p(si)先验怎么理解?实际怎么应用?
答:先验可以通过统计训练数据对齐的状态得到。唤醒任务不用先验。有些模型也会忽略,比如kaldi chain model。如果不要的话DNN的输出结果p(si|ot)就直接等于gmm的likelyhood p(ot|si),用这个直接做viterbi解码即可Q2 解码
问:DNN输出的概率是p(Si|Ot),解码怎么做呢?
答:用贝叶斯公式将p(Si|Ot)转换为p(Ot|Si),然后再用viterbi算法解码。P(Si)可以由训练数据的对齐统计而来,称为状态的先验。
问:在HMM-DNN中,我们使用DNN直接将观测对应到了隐状态,也就是得到了p(si | ot),这就是我们采用Viterbi解码想要的东西了(Viterbi解码就是根据观测找到对应的状态序列)。为什么实际上还要通过bayes公式利用p( si | ot ) 求出 p(ot | si )然后再走Viterbi解码这条路?
答:语音识别的目标是P(W|O),给定观测序列O,找到最可能的词序列W。在DNN/GMM-HMM框架下,你是受到HMM结构,语言模型P(W)跳转等约束的。你只考虑P(si|ot),给定特征帧产生某个状态的概率,你的状态序列是无法组成有效的句子的。Q3 作业
问:thchs30里language model的训练语料是什么?实际中怎么操作?
答:训练集的标注就是训练语言模型的数据。实际中看情况。比如说你在做标准数据集和别人比结果,那你就只能用那数据集合(比如说swbd,如果只是比这个数据集,那通常只用原本语料;但是也可以用swbd+fisher数据,这样效果更好。看task)。但是如果你是大公司的线上系统,你能收集多少数据就收集多少数据,一般来说,越多越好。只要注意不把test集合加进去就好。这个主要是让你们体验一下流程,熟悉一下工具包。因为实际工程对于成熟的算法,你用现成工具多;有新idea,才需要自己写。
-
学习讨论总结_第五章
——来自《语音识别:从入门到精通- 第一期》·77浏览
Q1 建模思想
简单的说一下。假设你想构建一个GMM-HMM系统,你对每一个phone定义了HMM模型,这里你就要估计HMM中的转移概率参数矩阵,和用GMM建立的发射概率(显然,不管是初始化还是训练到某一步了,你的参数都已经有一些值了)。
训练的时候,你做的第一步是把每一句“word-level的语音标注”通过字典扩展成"phone-level的标注",再扩展成"HMM的链式结构",这样对于每一句,你有了一个依赖于这一句的标注的一个特殊的HMM链。之后你进行viterbi training(或者forward-backward training)。
我这里用viterbi training举例,你先用viterbi算法(配合当前模型的参数),把每一个语音数据在它对应的HMM链上进行viterbi解码,这样获得了哪些语音帧对应哪个状态,也就是“对齐alignment"。(试着想象,你有5句话,这样你可以分别获得这5句话的对齐)。
接下来,你开始更新参数,这里你更新参数的时候你需要注意的是你用到的是整个数据集,而不是单一一句话。比如说上面说的你一个数据集有5句话,你要更新某一个HMM状态对应的GMM参数时,你是把这5句中所有对应这个HMM状态的数据都拿来估计。
之后你更新转移矩阵参数,把对齐计数转换成概率,可以看一眼ppt里面的公式。而对于GMM参数,你有了对齐(也就是每一个HMM状态对应哪些语音数据帧),你在对应的模型上用EM算法就可以解决(e.g. 假设你GMM只有一个Gaussian,那么你更新这个GMM参数,就是把这个语音帧计算均值和方差,替换原来的参数;如果是mixture Gaussian,你用当前参数和数据,求出每个Gaussian分量的概率和需要更新的均值方差,你可以看PPT回顾一下。)
比如你有5句话,每一句话都有"A"这个音素。第一句话有x帧数据,第二句有y帧,等等。你更新"A"这个音素的HMM模型时候,肯定是"x帧+y帧+..."一起都用上。假设对于"A"音素的第一个状态,你通过对齐,从第一句中有x1帧,第二句有y1帧,等等,那么你更新这个状态对应的GMM时候,是用的"x1帧+y1帧+..."所有特征(e.g. MFCC),去算分量,均值,方差。
Viterbi training和forward-backward training实际效果差不多,只是forward-backward里面每一帧对应哪个状态是一个概率,你要用forward-backward去求,你可以想想这个dynamic program最后是一个2维的网;但是Viterbi training,让某一帧对应某一个状态,是硬分类,也就是一条线。Dan试验过,实际上forward-backward算出来各个状态的概率会比较sharp,也就是一个很大,比如0.8,很接近1。这也是为什么两种方法都有效。但是显然Viterbi这种一条线的情况处理起来更简便。
逐一样本缺点在于,每一个样本数据太少,如果哪句不是很好,很容易就把模型拉偏了。但是如果你有很多语料,统一进行统计,大数定理表明比较稳定。举个极端例子,比如你抛硬币,第一个样本就抛一次,你这么更新不是模型认为硬币都是正面了。所以全局统计比较好。问:三种场景下HMM的state, observation到底都是啥?
答:对于孤立词,每个word对应一个HMM;对于单因素,每个音素(e.g. a)对应一个HMM;对于三音素,每个三音素(e.g. a+b-c)对应一个HMM。问:孤立词识别中是否可以用不同长度的状态建模长短不同的词?比如“开灯”用3个隐状态,“小爱同学打开电视”用6个隐状态?
答:HMM状态数是可变的,也不一定每一个都一样长,对于长的发音你可以用长一点的状态数。我以前在英语phone上做过实验,根据统计,做一些变长,某些音素状态多,当然没有你这个小米的例子这么差别大。有一点点效果,但是不很大。再举个例子,不同工具包对于不同音素定义长度也不一定一样。以前HTK,可能sil这种静音音素就用1个状态;Kaldi就用了5状态。问:以孤立词为例,三状态的HMM中每一个状态代表什么?
答:首先我们应该明确HMM的建模单元和状态个数实际是可变的。在这里,建模单元是word,然而你把word拆开成音素,对音素建模也是可以的。通常你到底选择怎样的建模单元要看你的任务难度,语料数据量等音素。这里十个数字差异性比较大,你HMM建模的颗粒就可以比较大。 状态个数这里取3个,你取4,5个也是可以的,3个有效状态通常是语音识别里面建模一个音素的习惯。整体的来看,一个HMM建模了你建模单元(i.e. 在这里是一个word)的发音过程。如果你非要说每个状态对应什么,这是没有确定结论的,就像状态个数也是个超参数可以改变。如果一定要一个形象的概念,你可以这么感觉,第一个状态就像气流发音在胸腔,第二个状态就像气流在喉部,第三个状态就像气流在口腔,但注意我们只能说这是一个形象的揣测过程,并不是一个一一对应的确定关系。问:如何建立观测(MFCC)和隐状态一一对应的关系?
答:(1)在这里要区分【隐状态】和【HMM每个状态】的区别。举个例子,在你学HMM那一章,应该讲了如下概念,隐状态序列 I=(i1,i2,...,iT)和观测序列 O=(o1,o2,...,oT),两者等长,一一对应。HMM的每一状态形成一个集合 Q={q1,q2,...,qN}。N与T无关。这里的隐状态描述的是某一时刻你处在某一个HMM状态上,就如你在转移矩阵定义里看到的 aij = P(it+1 = qj | it = qi),这里it = qi描述的是你第t时刻处于HMM状态qi。打个比方,对隐状态序列O做一个“求集合的操作,可以得到HMM的状态集合Q (2)序列中有多少个状态取决于分帧分出多少个帧 (3)对于embedding training,你先有了这100帧数据对应的标注抄本。比如你的抄本是单词'he',你HMM的建模单元是monophone(HH IY),那么你可以感觉字典把he展开成一个HMM链,即 HH_state1->HH_state2->HH_state3->IY_state1->IY_state2->IY_state3,这里每个state都有自环,当你训练好了模型,你拥有转移矩阵和每个状态对应的概率密度函数(i.e. 发射矩阵)。你在这个HMM链上进行viterbi解码,你可以获得每一帧对应到哪个HMM状态。换句话,你获得了隐状态序列。
至此,你知道有隐状态序列 I=(i1,i2,...,iT) [每个it对应HMM一个状态] 和观测序列 O=(o1,o2,...,oT) [每个ot对应一帧MFCC]。你自然可以用MLE方法更新每个状态的概率密度函数和HMM的转移矩阵。问:每一个建模单元(孤立词/单音素/三音素)对应一个HMM的话,建模单元之间的转移概率如何建模?
答:通常你会有语言模型和字典。语言模型描述了word之间转移的概率,字典描述了一个word对应的一种或几种音素串。假设你的建模单元是phone。想象你有一个句子标注(i.e. word sequence), 这样你可以根据LM的概率指导word之间转移概率。之后word内部,你根据vocabulary扩展,如果只有一条路径,你建模单元phone之间的转移概率为1,如果多音字,转移概率通常会是统计出来的,进入下一个建模单元phone的概率。问:单音素和三音素的GMM有什么关系?
答:可以用单音素训练出来的GMM参数做初始化。假设A是根结点,A对应某个单音素的一个状态,A经过单音素系统的的训练已经有了其GMM参数。现在A分成了A1和A2,现在要估计A1和A2的GMM,但需要一个合理的初值,就可以直接使用A的参数值作为初始化。问:三音素的表达,为什么写成A-B+C,其中的加、减符号有什么特殊意义吗?
答:没有特殊含义,如果你愿意A+B-C在HTK里面也这么写。对于三因素,你应该留心它的中心音素,上下文context,而不单纯是记号。Q2 训练
问:训练的时候每个状态所对应的观测状态(mfcc)又是怎么来决定(难道是每个单词的wav文件三等份,然后求mfcc,在给对应的观测状态吗)?
答:提取MFCC的时候要考虑到语音的短时平稳性,通常我们我们会选25ms的窗长,10ms的帧移来提取MFCC。比如说1s的音频,你会获得100帧。假设你知道这1s的音频对应的是数字one,那么你就用这100帧mfcc数据来训练one对应的HMM模型。训练方法就是之前讲过的forward-backward和EM算法,或者开拓老师讲的时候提到的embedding training来更新模型参数。[简单的帮你回顾一下embedding training,它把这100帧强制对应到了某个状态,比如1-40对应第一个状态,41-75对应第二个状态,76-100对应第三个状态。之后你用对应帧的mfcc参数更新对应大GMM模型就可以了。
问:语音识别中的GMM-HMM都是一个左右的HMM系统,也就是状态1只能自转移或转移到状态2,不能转移到状态3。那我们初始化的时候,a(状态1->状态1)和a(状态1->状态2)不等于0,其他从状态1转移出去的的概率要设成0。那GMM-HMM经过多次更新后,仍然可以保持,其他从状态1转移出去的的概率等于0么?
答:是的。这部分和训练无关,相当于没有这个参数,不会被更新,所以一直是0.问:训练过程不用标注的抄本可不可以?gmm-hmm训练是无监督的,dnn训练用gmm-hmm强制对齐后的标注结果,那为何还需要进行语音数据标注,标注结果用在什么地方?
答: 对于gmm-hmm训练你可以认为是无监督的。为了解释方便,这里我假定你HMM的建模单元是phone,你有lexicon(i.e. 你知道word与phone sequence的对应关系)。假设你没有抄本,你可以想象,你第一帧会到所有word的第一个状态,换句话说所有HMM的初状态,之后你每一帧会根据HMM进行跳转,也就是说,你每一帧大概都要计算到所有音素的各个状态。但是,加入你有抄本(i.e. 语音数据标注),你就可以对状态进行限定,你第一帧走的不再是任意状态,而变成了抄本里第一个词对应第一个音素的第一个状态,这样大大缩小了你的搜索空间。此外,目前训练策略较多采用embedding training,这里生成一个强制对齐。而且,你dnn获取强制对齐也是需要抄本的,你可以根据抄本,获得一条或者很窄的一束将phone level HMM进行连接的HMM链。这样你在上面用viterbi解码获得强制对齐结果。对于强制对齐,如果你没有抄本,只是用viterbi进行解码,可能你获得的是一个错误的对齐(e.g. 你把"It's a word"对齐成了"Eats a world"),这样你后面的训练也会跟着错。Q3 解码
问:解码的时候HMM状态转移概率矩阵是怎么用的?每个状态都有3个音素,状态转移矩阵岂不是超级无敌大?
答:概括的讲,实际上连续语音识别,你会有一个语言模型,它建模P(w_now | w_history),这个概率确实很多,是统计出来的;然后你有一个字典,它做word和phone sequence之间的映射。再结合你现在了解的对每个phone建模的HMM,你可以把每一个word展开成HMM状态上的链接。你可以借助下图理解: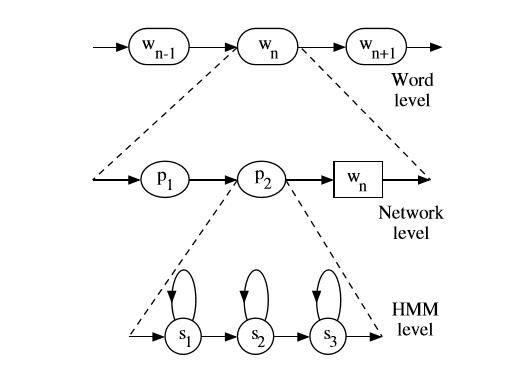
通常具体实现中,会给每一个3状态的HMM的头尾添加一个没有发射概率切没有自跳的状态,方便phone之间的链接(当然不同工具包不一样,HTK是头尾都加,kaldi你可以理解为只有在尾部添加),这主要取决于实现者。这个彬彬应该在课程里提了。
假设,类似kaldi,我们每个HMM有一个final状态,从音素的第三个状态跳转到final就是一个HMM内部问题,然后从final状态跳转到下一个音素的第一状态,普遍上概率为1,但是有时有多音字情况(这个准确的说,是因为在一个word内,根据字典,你已经明确的知道了下一个phone是什么,所以这一步的跳转概率为1。但是比如一个字有多种发音则只是概率和为1(比如word1的发音为"a b c"或“a d c", 那么从a的final状态跳转出去到b或者d,只是概率和为1,分别的概率通常基于统计)。这样我们就解决了word内部HMM的跳转。
对于word之间的跳转是由语言模型上的概率决定的,这确实很多。当然这里在实现上还有很多技巧,否则你从一个word理论上可以到字典上任意一个word(可能有成千上万), 一般会用比如phone-level prefix tree等方法来处理,等等。
在词内,比如你有一个字'好(h ao3)',你对音素建模h和ao分别有自己的HMM,在'好'这个字内,你自然是知道从h的最后一个状态跳转到ao3的第一个状态。
在词间的时候,是由语言模型决定的,比如'好'可以跳转到'人(r en2)'这个字的第一个音素'r'的第一个状态,到'事(sh i4)'这个字的第一个音素'sh'的第一个状态等。当你处在'好'的最后一个音素'ao3'的最后一个状态后,你确实存在要跳到很多字的第一个状态的可能,理想化的可一个是vocabulary的任意一个字,当然prefix-tree等方法会进行一定处理(就像你说的简化跳转到每一个音素)。
对于LVCSR来说,解码图的确很大。识别时候,你可以想象成你先有一个word级别的跳转关系,然后每个word可以根据字典展开成hmm链。
问:gmm-hmm解码过程中如何实现音素到词的映射?
答:做解码的时候还是有限制的--和你做对齐一样,它都需要有一个图。只是对齐的时候图是由抄本扩充的,比较小(这里图就是HMM链,对齐之前你要把标注抄本扩展成HMM链,我们实际工程一般用wfst图表示,所以也称之为图。解码时候也有这样一张wfst的图,称之为解码图);而你解码时候图是从LM得到的,你可以简单的理解成字典里任意两个词跳转(当然词典里不是任意两个词都有跳转关系,所以稍微小一点),比较大。显然的它规定了你解码的范围,不会超出你字典里的词。这样理论上,你在每个word对应的HMM链后面加一个word的终止状态,你就能知道这个word对应的音素结束了。实际情况里,为了简化图,会合并公共前缀,然后加消歧义符"#..."。问:解码过程是一个自底向上的过程?
答:不是的,它也是要有搜索范围的,需要LM形成的图来约束。只是表面上粗略理解为自下向上。实际上的做法是LM扩展成图,然后feature在这个图上跑,形成隐状态序列,有点像两头同时出发,然后中间夹出来结果,这么个感觉。
【在解码里我会讲:让我们看看没约束的情况:你有一串MFCC,你每次都把一帧MFCC带进所有状态的GMM算概率。这样你能得到这一帧最可能属于哪个状态。比如第一帧最高的是a音素2状态,第二帧是b音素1状态。他们是连不成一个音素的!所以你要约束,让第一帧是某个音素(e.g. a)的第一个状态,然后第二帧只能是该音素(e.g. a)的第一状态或者第二状态,依次类推。所以你要有一个由各个音素的HMM约束的解码图,既然你可以有这种图,相似的你也可以有由各个词约束的解码图。】Q4 决策树
问:在训练一个三音素GMM-HMM的时候,语音决策树是不是要在训练GMM-HMM之前就要搭建好?
答:是的问:训练之前,一个状态对应的特征向量都是在帧级别上进行均分的,而这个均分的结果是很不准确的。如果这样,利用PPT中30页极大似然增益的方法搭建决策树可以得到正确的决策树么?
答:状态所对应的特征向量是由单音素系统对齐产生的,已经有很高的准确性问:Kaldi中通过自顶向下的聚类自动构建问题集。那过程我理解是这样的: 假如现在根节点是一堆以zh音素为中心的第三个状态, 那么kaldi中会遍历所有问题(比如左边是不是鼻音,或者左边是不是摩擦blabla的),然后对应极大似然增益最高的问题作为这个节点的问题,然后二分类,然后依次重复这个过程?
答:是的问:视频中93:10开始讲解说:对单音素的第一个状态建决策树,下面93:38有一句说“刚开始的时候只有一个,就得想办法变成两个。”这句话的意思是不是:现在所有的训练数据S中的三音素对于该单音素的第一个状态来说,都是同一类,要想办法将它们分成两类?
答:是的问:决策树算法是在解码时执行?训练时不用执行吗?如果训练时也执行,是在执行完对齐操作,得到了每个状态节点所对应的训练数据S,然后开始进行分类?这个操作是一次完成的吗?和对齐操作一起迭代吗?
答:决策树是在训练时构建,训练和解码时都会使用到。训练时随着模型的更新迭代,对齐也在更新,决策树也可以迭代,但一般仅需要一次或几次迭代就行。决策树使用对齐作为输入,并不会更新对齐,使用更好的对齐,迭代后的决策树会更准确一些,相当于你有一个更精确的三音素聚类。问:构建决策树的input 和output分别是什么,可以明确定义一下吗?
答:决策树的输出决策树,输入是一个个的单音素的状态和该状态所对应的所有训练数据。
问:单音素和三音素决策树的输入都一样吗?都是一个个的单音素的状态和该状态所对应的所有训练数据?三音素是每个状态节点对应一个三音素,那构建决策树的时候,是对中间的那个音素构建决策树?比如节点A-B+C的第1/2/3个状态,都是对B构建决策树?
答:三音素需要决策树。决策树的构建以状态为基本单元,比如B音素的三个状态都有一个小的决策树。Q5 作业
问:转移概率arc.get_log_prob() 取到的数都是0.000000,这是什么问题呢?
答:这个作业设计里面转移概率的log值是0,可以理解为一个状态他的自跳和跳出概率是一样的,都是0.5,所以每一条边上的概率也相同,是取log(0.5)还是0都不会对最终结果产生影响。问:add_log_probs 函数的作用?
答:实现log域的概率相加。A*B取概率乘是log(A)+log(B),但概率加A+B的log概率就没这么直接,需要有专门的函数计算,add_log_probs就是做这个。问:对于fsm to graph,下面的srcIdx, dstIdx, gmmIdx, wordIdx中的前两个该如何理解?
srcIdx dstIdx gmmIdx wordIdx
1 9 0 EIGHT
1 6 6 FIVE
1 5 15 FOUR
1 10 24 NINE
答:src起始状态,dst目标状态,这是上课是说的FST形式的HMM表示,可以参考http://www.openfst.org/twiki/bin/view/FST/FstQuickTour#Creating%20FSTs%20Using%20Text%20Files%20f问:在孤立词解码中初始状态到每一个音素的第一个状态,还有每个音素的最后一个状态到终止状态的概率怎么设?get_final_state_list 方法为什么返回的是个列表,并不是一个?
答:这里转移概率大家设成一样就行,取哪个值都行,在log域计算的时候一般都取0。多个终止状态可以有,后面讲解码图的时候会讲到。
问:fsm文件如何理解?文件中的数字是否可以认为是HMM中的隐状态?比如第一行1 9 0 EIGHT 是不是理解成从开始状态跳转到9状态,并且9状态绑定的高斯序号为0?
答:这是WFST形式的解码图,这是其中一种文本表示的方法,每一行的格式是,具体的还可以再参考http://www.openfst.org/twiki/bin/view/FST/FstQuickTour#CreatingFsts问:fsm文件是按照单音素建模的吗?并且每个音素对应于三个HMM隐状态?如果是这样的话,比如对于EIGHT这个词,应该总共有2个因素,状态个数是2+2*3=8,应该不止文件中的1 9 0三个数
答:是单音素建模,剩余的参考上面的fst介绍就可以。问:文件中的<epsilon>是什么意思?
答:表示空问:请问p018k1.noloop.fsm和p018k1.noloop.pdf是对应的吗?1 9 0 EIGHT按说明起始状态应该是1,目标状态是9。但是pdf里面是从0开始到1
答:本来是FSM的结构,用FST画出来就长这样了,整体的id都减了1 -
学习讨论总结_第四章
——来自《语音识别:从入门到精通- 第一期》·53浏览
Q1 建模思想
隐状态/观测分别为连续/离散,排列组合有四种,隐状态=离散的两种叫HMM。初学理论常用案例中观测=离散,语音识别中常用的是观测=连续(GMM)
问:为什么用GMM来表示HMM的观测概率?
答:因为GMM是一种具有良好性质的连续函数,可以近似拟合任意分布。每一个隐状态对应一个连续的分布函数(区别于观测是离散的有限集合),数学描述即是一个GMM(一组高斯)问:既然HMM的发射概率可以是连续或者离散,HMM的状态可以是连续的吗?
答:状态如果是连续的,这个模型我们一般称之为Kalman Filter(线性)和Particle Filter(非线性)。Q2 HMM理论
问:为什么后向算法解决evaluate问题beta=1
答:因为根据定义,T+1到T的部分观测序列不存在,所以规定为1问:为什么viterbi算法需要回溯过程,递推过程中没有把最优路径都算出来吗?
答:因为递推过程中,每一个时间节点上都得到了很多个最优路径(并不唯一),只有到了最后一帧才能一步一步的推出来最优的一条路径(排除掉其他的)Q3 HMM实现
问:kaldi中hmm训练单音素和三音素声学模型时,用的是Viterbi还是Baum-Welch学习?
答:Viterbi -
置顶 精华 学习讨论总结贴集合
——来自《语音识别:从入门到精通- 第一期》·275浏览
这个帖子将会对大家在微信群/讨论区讨论的问题进行分章节的整理,便于大家回顾和巩固。
-
精华 学习讨论总结_第三章
——来自《语音识别:从入门到精通- 第一期》·98浏览
Q1 GMM理论
问:为什么孤立词识别是每个词一个GMM,而不是只用一个GMM,每一个高斯分布来表示一个词
答:因为单个高斯分布这个函数太简单了,表达能力不足以区分不同词。
问:请问孤立词识别任务中GMM中的k个高斯成分对应的隐变量有实际意义吗?是不是就对应到音素上了呀?
答:其实这个k在这里,是没有太多实际的意义的,后面当你们学习到HMM-GMM时候,HMM的每一状态你可以认为是对应到某一个子音素上,但是GMM咱们这里没有这个对应。
Q2 EM理论
问:EM算法的Q函数如何理解?
答:公式11中,我们看到Q函数,实际上是ln p(X,Z|theta)这个联合分布关于Z的期望,虽然看着很复杂,但是本质上,还是对Z这个变量求期望,里面的X,theta,你都可以看成无关的变量,比如一个公式是f(x,y) = x+ y, 如果你对x求期望,E_x [f(x,y)] = E[x] + y, 因为y和x无关
Q3 GMM实现
问:GMM如何选取合适的k值?
答:当你后面学习的过程,会发现,其实k的值并不是从一开始就固定的,一般对于一个复杂的系统,都是k先设置成1,然后逐渐增加k的值,直到满足某个准则,比如当发现所有模型的总体的高斯数的和已经到了某个阈值,或者再增加k,似然也不上升了。但是这都需要调参数的过程来确定
问:第三章作业代码中对于每个词的初始化(kmeans)都用了所有的数据而不是对应词的数据,虽然在后续没影响,但是为了更快收敛的话不应该用对应词的数据更好么?
答:对我们这个小的作业来说,并不重要,一般像HTK,初始话的时候,都是将一个句子平均分以下,每个模型用一部分数据初始化。
Q4 实际应用
问:数据中语音段前后静音帧数目会对训练测试结果有影响吗?比如训练集语音段的前后静音帧很多,而测试集语音段前后静音帧很少,这个测试结果会变差很多吗?
答:确实会有影响,这种不匹配程度大的会变差很多。我们这次作业中提供的数据,都是很简单的录音,也很干净,但是实际应用中,您提到的这个问题确实存在。
问:使用作业的GMM去预测连续语音,结果如何?孤立词识别是不是跟唤醒词识别有关系?
答:预测结果会是target中的任意一个,因为我们目前只有11个类别,任何语音,即使和我们的目标语音完全无关,也会根据计算的似然结果,选择最大的这个,如果你想处理这种情况,你可以再加一个模型,表示除了这11个类别外的任何语音,但是这个模型就需要大量其他数据来训练,我们叫他“垃圾”模型。再者来说,咱们作业的这个简单的模型,也不合适连续语音识别,每个GMM(0-9,o)都是用它对应的语音数据训练,测试的时候,也只能整段语音分帧、加窗、提特征,然后在每个GMM上,计算每一帧的似然最后求和得到最终似然。
问:孤立词识别和唤醒词识别有什么关系?
答:如果你说你就有两个GMM模型,一个是唤醒词模型,一个是除了唤醒词之外的其他数据的模型,那么这个可以看成是唤醒任务,但是一般不会这么做的,一般也是和HMM结合来做。
-
精华 学习讨论总结_第二章
——来自《语音识别:从入门到精通- 第一期》·85浏览
Q1 预加重
问:滤波器的传递函数写成是H(z)=1-z^-1,为什么这个形式就是高通滤波器,以及这个传递函数形式如何能够跟时域上差分的形式形成联系?
答:是的,这个确实是一个高通滤波器,如果你对传递函数不是很理解,那么你可以这样理解:公式y[n]=x[n]-a*x[n-1],试想,如果x[n]这个信号频率很低,那么x这个信号变化很缓慢,x[n]和x[n-1]的差别是不是应该特别小?当a这个参数接近1的时候,x[n]-a*x[n-1]是不是近似于0了,这样就把频率比较低的信号通过这种差分形式过滤了。如果x[n]这个信号变化很快,也就是频率高,那x[n] 和x[n-1]的差别应该很大,做差分就无法滤过这个信号了。这是一个通俗的说法。
问:预加重,‘提高信号高频部分的能量‘ ,在语音信号中,高频一般是噪音,应该采用低通滤波除去,为什么这边反倒加强了?
答:语音信号的高频并不是噪声,比如元音,有很明显的谐波,但是高频信号由于衰减快,录制到的高频谐波能量很低,而人耳又对高频部分相对敏感,因此我们通过预加重,来提高高频部分的能量
问:预加重的系数alpha的大小对预加重的影响是什么?
答:由于spectral tilt(也称为声谱斜移)现象,低频的能量比高频的能量高一些,在语音识别里,预加重高频端的能量可以使模型能更好的建模高频信息。公式是y(n)=x(n)-ax(n-1),通常a取(0.9,1)。当a特别小的时候高频能量提升不明显。你可以自己画一个sound pressure level的图感受一下,变换后高频的能量会明显提升(比如从-40dB/Hz到-10dB/Hz,这只是个例子)
Q2 DFT
周期性
对一段信号进行时域上的采样,相当于原始信号和周期为t_s的脉冲信号进行相乘,在频域上,则表现为两个信号的卷积,周期为t_s的脉冲信号变换到频域,仍然为周期的频域脉冲信号,如果将此信号和原信号的频域信号卷积,则会导致频域的周期性;第四问是因为时域上信号是周期的,那么在一个周期内,采样点个数N一定是有限的,而DFT两个频率之间的差为f_s/N,N如果有限,那么f_s/N则是有限的数,此时频域就是离散的。但是,当N趋于无限的时候,f_s/N趋向于0,频域则为连续的。
因为DFT的结果是周期信号,所以只要把任意一个连续的长度为N的周期计算完整,剩下的地方补0或者延拓就好
问:X(m)相当于谱密度的说法怎么理解?
答:如果某一个时域信号中,包含了某个频率为f,幅度为A的正弦波,如果对这个信号进行N点DFT,那么DFT之后,在频率为f的那个索引m上 (m*fs / N ==f), 对于的DFT的幅值|X(m)| = AN/2
问:补零的操作是怎么回事?
答:一个长N1的时域信号,补零之后,为N2,对两个信号做DFT之后,如果两个信号的m1/N1 = m2/N2,那么就说这两个索引点m1和m2表示的频率相同,很明显,在DFT的公式里,第一个信号的X(m1) = \sum_{n=0}^{N1-1} {x_n e^{-j2pi n *m1/N1}}, 补零后的第m2个点的DFT X(m2)= \sum_{n=0}^{N2-1} {x_n e^{-j2pi n *m2/N2}}, 因为m1/N1 = m2/N2, 两个公式里x_n都一样,只不过第二个信号的x_n里多了尾部一些0,对于此频率点,两者得到的结果一样。原来时域有400个点,再在后面补112个0,形成512个点的时域信号,然后做512个点的DFT,然后取512个点的DFT的前257个点。
问:一种是说补零会改变频率分辨率(因为点数多了),还有一种是说不会改变分辨率,只是可以改善栅栏效应,能够观察到更多的频率细节。不知这块该怎么理解?
答:举个例子,比如一个离散信号x[n], 长度为K,这个离散信号中包含了两个频率为f0和f1的正弦波,两个频率很接近,并且原始的K个采样点已经包含了频率较低的那个正弦波的至少一个周期(当然也必然包含了较高频率的至少一个周期),那么此时增加DFT点数,补零的操作,使信号补0到N个点,如果fs/N < |f1-f0|,那么此时,肯定可以提高分辨率,把原来K个点DFT无法分离的两个频率成分给分开。这也是我个人的理解
问:page 22中由于我们dft是在一帧信号上进行的,所以我们得到结果也就是最底部左边的那个图不是右边的语谱图的切面,而是一个矩形,矩形的长的25ms,这样理解对吗?
答:底部左边的图,确实是一个25ms的时域帧DFT之后的频谱,我们完全可以用语谱图在某一个时刻上的切面来理解语谱图的意义。
Q3 分帧/加窗/频率泄漏
问:分帧提取特征和小波分析有什么区别?
答:语音识别的时候都需要以较小的发音单元进行识别,一个发音单元内信号平稳,当两次音素连在一起的时,就出现非平稳信号了,但是这种两个音素,又不符合我们识别的需求,因为我们是一个音素一个音素的识别。
加窗的目的是为了分帧,但是会来带来混叠。重叠是因为窗函数呈钟形,当原始信号乘以窗函数后,不可避免的引入了幅度上的加权,导致靠近窗函数首尾的信号被衰减,从而导致分帧后的频谱不再是原始信号的频谱。因此,采用重叠的方法来解决这一问题。保证原始信号不会丢失某些成分。
分帧时是信号和窗函数相乘,频率上是信号频谱与窗频谱卷积,如果窗函数旁瓣比较大,则会出现卷积后的频谱在旁瓣处也会比较大,恢复原信号时越完整的频率信息越能恢复原来信号。但我们做采样时采样率已经限制了我们信号的频率带宽,fft时也不能用少量数据点输出很高精度超过原始信号带宽的频率信息。所以造成旁瓣处的频率不能参与表示原信号,与原信号失真,旁瓣越大失真越大
Q4 Mel滤波器组
问:为什么mel滤波器低频窄高频宽?
答:低频上滤波器比较密集,人耳对这部分的分辨率是比较高的,高频信息,特别是谐波,对识别音素很有帮助
Q5 建模单元
信号一般具有短时平稳特性,特别是你观察一下元音音素,一个音素之内信号是有周期性的,我们进行识别的时候,hmm模型也是音素级别的建模,hmm状态表示了比音素更小的单元。
在hmm中大多数是一个状态对应多个帧。
问:目前有用syllable来做建模单元的吗?
答:目前hybrid的方案(gmm-hmm or dnn-hmm)都是更小颗粒度的phone; 课程后面讲到的end to end 的方法(比如CTC,transformer,las,rnnt等)可以用更大颗粒度单元(比如syllble, character,或者wpe)
Q6 MFCC/Fbank标准计算流程
对DFT之后的谱特征进行滤波,其中谱特征等价于取模的特征
fbank特征需要进行幅度转db吗?不需要,取对数就好
为什么MFCC取13维?
因为前面几维描述了原始频谱的形状
问:MFCC的最后一步是idft,是傅立叶变换的逆变换,那就是把之前dft变换到频域的信号,再次变换回时域。如果是这样,那么page 26的那3个谱图的横轴就应该是时间了?
答:这个地方,并不是直接把之前dft的频域信号直接变回时域,是经过了梅尔滤波器、log之后的信号,再次变回“时域”。我们ppt里面用了伪频率轴,其实是说,这个idft之后的信号,并不是真的表示有明确意义的频率,我们实际上是把log X当作了一个时域信号处理(虽然他是频域的,但是如果我们把横轴看成时间轴呢?),是不是相当于又对log X做了一个DFT?因为这个信号是实数信号了,dft和idft其实一样
问:fbank特征经过IDFT之后得到的n维MFCC特征中每一维分别代表什么?哪些是原始特征,哪些是一阶,二阶,能量特征?这样做的物理意义是什么?
答:从我们课件的第27页我们知道,我们的目的就是为了分开log |X|中“低频”和“高频”信号,log |X|本身就是一个频域上的信号了,但是如果我们忽略这个信号的本身表示的意义,就把它当成一个普通的波形来看,如果你想分析这个信号的频率成分,应该怎么做呢?很简单,就是对这个信号做一个DFT分析,这样,我们就知道这个信号里面低频和高频信号各有哪些了,这就是我们做了idft的作用,因为这个信号是实信号,idft和dft其实是一样的。27页的ppt中,log |H|变化缓慢,很显然,这个就是log |X|这个信号中的低频信号,也是我们需要的部分,那么,IDFT(log |X|)得到信号的前半部分就应该是这个信号的频率成分了,同理,后半部分就是对应的log |X|中频率较高的部分了。比如经过idft之后,我们只取了idft之后的第1-12位,那么这1-12位就是最原始12维MFCC特征,至于一阶,二阶,那就是用相邻帧的12维特征进行一阶差分和二阶差分进一步得到的。能量,就是原始时域信号x[n]的能量和 sum(x[n]^2)
问:mfcc中对取模以后的实信号DFT和IDFT有什么区别?
答:没有区别。倒谱分析的公式中,就是对某一个信号的FFT的log abs (X) 做IDFT,我们在计算fbank的时候,实际上只用了一半的频率,如果做IDFT,需要把另一半也补上,这样这个fbank特征就是实对称的了,那么不论做DFT还是IDFT,最后不会有符号差异,因为虚部被抵消了。系数的差异会有,但是对于所有信号来说,都是一样的差异,不会影响。
Q7 MFCC具体实现
kaldi里面,会把13维MFCC特征中的第0维剔除,换成我们时域重新计算的能量
问:关于能量的维度我看ppt是取原始信号的平方和,有的是用频谱取模平方除以一帧的点数,还有取对数的这些应该都一样吧?只是一种量化能量的方法?
答:不同代码实现方式不一祥,他们都代表能量,就是一个scale问题
问:librosa中的生成mel滤波器的接口mel_basis = librosa.filters.mel(16000, 512, 20, htk=True)中的htk参数True和False有什么区别?
答:False的时候对每个bin做了一个归一化,使每个filter bank的能量和大致相等
问:kaldi的aishell recipe中,MFCC_Pitch有什么不同?
答:多了一个3维度pitch提取的部分,其他的就是标准的mfcc
Q8 MFCC Fbank可视化
画图的方向:通常横坐标表示时间,纵坐标表示频率
Q9 实际应用
问:MFCC特征一般用于对角GMM训练,Fbank特征一般用于DNN训练,能详细介绍下这是为什么吗?
答:MFCC特征做过了DCT变换,我们说各维度之间的相关性变小了,而我们在训练GMM模型的时候,一般高斯模型的协方差矩阵是对角的,也就是说,变量的各维度之间是不相关的,而MFCC特征基本上有这个属性,特征的各维度之间相关性小了。
但是fbank特征,因为各个滤波器之间的重叠,还有就是信号频率之间的相关性,比如谐波的存在,各维度之间相关性比较大,但是DNN的建模的时候不需要假设各维之间是不相关的,因此直接采用fbank特征就行。
问:近讲和远讲语音,特征抽取有什么不同吗?
答:目前来看,其实近讲和远讲在特征提取部分,是没有什么区别的,虽然远讲信号能量衰减快,一般是利用前端语音增强技术来增强语音,降噪、AEC、去混响等等,但处理之后的信号还和课程讲的一样进行特征提取。
问:端到端的深度学习的语音识别和传统的语音识别特征,有什么不同? 未来的深度学习的语音识别不需要特征抽取这个过程了吗?
答:1. 端到端的识别,所使用的特征其实还是我们目前讲的特征,fbank特征最常用
2. 其实还是需要的,目前直接用wav建模的模型,效果还是不如基于频域的特征,就算是相关研究,也还是利用CNN来学习滤波器的特性
问:在远场语音识别任务中,语音高频损失很厉害,这个时候是不是高频特征的信息会反而不可靠了,还是说依旧要保留高频特征进行训练呀?
答:现在几乎所有的模型,还是会进行预加重的,并没有因为这个原因放弃这一步,我理解的是远场的时候,高频衰减比较厉害,应该更需要做一些预加重,而且现实的噪声信号,中低频的多,这样也能稍微减弱一下中低频的干扰。
-
精华 学习讨论总结_第一章
——来自《语音识别:从入门到精通- 第一期》·68浏览
Q1 梅尔频谱
mel-scale spectrogram和linear-scale spectrogram有什么区别?mel是根据人耳特性分析得出的(非线性的)频率响应曲线
Q2 端到端语音识别工具包espnet
优化过的transformer一定程度上解决了显存爆炸的问题
有论文在espnet基础上增加了E2E-sincnet
Q3 音色vs音调vs响度
音高也称音调,表示人耳对声音调子高低的主观感受。客观上音高大小主要取决于声波基频的高低,频率高则音调高,反之则低,单位用赫兹(Hz)表示。频率低的调子给人以低沉、厚实、粗犷的感觉;频率高的调子给人以亮丽、明亮、尖刻的感觉。主观感觉的音高单位是“美”,通常定义响度为40方的1kHz纯音的音高为1000美。赫兹与“美”同样是表示音高的两个不同概念而又有联系的单位。 人耳对响度的感觉有一个从闻阈到痛阈的范围。人耳对频率的感觉同样有一个从最低可听频率20Hz到最高可听频率别20kHz的范围。响度的测量是以1kHz纯音为基准,同样,音高的测量是以40dB声强的纯音为基准。实验证明,音高与频率之间的变化并非线性关系,除了频率之外,音高还与声音的响度及波形有关。音高的变化与两个频率相对变化的对数成正比。不管原来频率多少,只要两个40dB的纯音频率都增加1个倍频程(即1倍),人耳感受到的音高变化则相同。在音乐声学中,音高的连续变化称为滑音,1个倍频程相当于乐音提高了一个八度音阶。根据人耳对音高的实际感受,人的语音频率范围可放宽到80Hz—12kHz,乐音较宽,效果音则更宽。频率对音高是决定作用,但是也会和整个发音过程有关。
问:page27页提到”口腔、鼻腔、舌头的位置,嘴型等决定声音的内容(即音色)”。这里说声音的内容就是音色是不是不太严谨,page39也提到了”声音波形的谐波频率和包络决定音色”。韩纪庆老师的书上说”声音之间的区别在于和弦”,和”基音和倍音有关”。所以音色具体跟音频的哪部分有关呢?特别地,改变提取到的声学特征(MFCC和LPC等)里面的哪些参量可以改变音频音色?
答:音色是一个主观的概念,没有太严格的定义。”口腔、鼻腔、舌头的位置,嘴型等决定声音的内容(即音色)” —》 这里的内容就是指这些发音器官的运动组合主要决定了发出来音的音色,而音色主要决定语音的“内容”(可以狭义的讲”内容“就是决定语义的,就是不同人说出的“今天天气不错”,可能音量不一样,可能调不太一样,但是大家都能从“音色”感受到是同样的语义内容。”声音之间的区别在于和弦,和基音和倍音有关“, 这句话也是对的,发不同音的时候,发音器官形状和运动性不一样,或者说声带特性不一样(比如震动频率,声门大小),且声道形状和发音器官位置不一样(即滤波器不一样),造成了倍音(共振)不一样。
问:音调是不是可以理解为人耳所能感知到的频率?它是不是也与口腔、鼻腔、舌头的位置,嘴型等有关?
答:可以这样理解,人耳感受到的音调(音高)和物理频率之间不是线性关系,近似一个log函数,这个是和整个发音过程都有关系(包括声带振动的频率和整个声道的滤波作用)
Q4 泛音和倍音是否是一个概念?
是的
Q5 包络&瞬态特性
问:page39里面说的”包络的陡缓影响声音强度的瞬态特性”。这句话太能理解:什么是声音强度的瞬态特性?(网上查了下也没查到)以及包络的陡缓是怎么影响它的呢?
答:声音强度的瞬态特性就是说(1)声音是时变的,temporal的,反映在频域里就是不同频率上的能量分布是瞬态的。(2)这里的强度是指在不同频率上的强度是瞬态的,但虽然是时变的,但是在一定时间段内又能保持一定的稳定性。比如我们语音识别声学建模的时候,选取音素状态(phone state),即子音素(sub phone)来建模,就是因为在子音素单位内,声音的瞬态特性可以看似是稳定不变的。
Q6 变声
问:如果我想改变音频的音色而不改变语义文本内容,是不是只要想办法改变基音和倍音在语谱图的相对位置就可以实现了呢?
答:是类似”变声“,不过这种变比较机械。有一个voice transformation的技术叫frequency warping就是类似的想法。西工大音频语音与语言处理研究组出品的变声案例,这是一个many-to-one的voice conversion。目前最稳定的方法是类似ASR+TTS的方法。
语音转换(voice conversion)的狭义定义是指:保留源说话人的内容信息,而让语音变得像是目标说话人的音色(内容信息不变)。广义的语音转换可以是: 念歌词 --》 唱歌(lyrics to singing); 中性情感--》高兴/生气 (情感转换),口音转换(普通话-->四川口音普通话).... 或者广义上叫 voice transformation
ps:voice conversion分类
- One to One:只能把某一个人的声音转换成某另一个人的声音
- Many to One:只能把任意人的声音转换成特定某一个人的声音
- Many to many:可以把任意人的声音转换成任意人的声音
另外还可以从语料上分类:
- 平行语料:转换前后是同一句话,比如转换前后都是“我是中国人”
- 非平行语料:转换前后可以不是同一句话
问:语音转换,对说话人识别有影响吗?
答:有影响。国际上有一个评测叫asvspoof, 就是针对说话人识别仿冒检测的。https://www.asvspoof.org/
问:在训练模型时是否有用到这些变声或变音色方法来扩充数据集呢
答:如果是指ASR的data augmentation的话,变声(变速+变调)是一种常见的方法,还有就是加噪声和混响,目的是提升数据的多样性。kaldi里也有标准的做法。还有谷歌最新的specaugmentation方法,在输入上随机mask调一段(time or frequency masking),也是一种可以看做输入”dropout“的方法,算是缓解overfitting的一种方案。
Q7 grapheme vs morpheme
问:中文里面的一个grapheme就是一个汉字,那英文的一个grapheme是一个单词还是一个字母?或者不一定一一对应?
答:morpheme对英文来说,一般是小到词根的。
Q8 波形上下不对称

这个没有必要对称,放大之后,就是点和点相连。图缩小之后,感觉是“对称的”。
上图这种不对称主要是硬件采集设备(如麦克风、声卡)采集过程中的失真导致的,拾音器采集声音的时候,本身就不会特别严格对称,可以通过调整直流偏移调整,和采样率没有太大关系。采样率只是影响音质和带宽。
问:如果强制把波形改成上下对称的会怎么样?(比如只取上半部分,相应的下半部分取负),那声音听起来会不一样么?
答:估计这样可能声音可能还有可懂度,但是听上去就比较机械了。 【话说传统的语音合成技术,基于简化的发音机理(比如源滤波器)的数学合成方式,出来的波形应该比较机械,缺乏细节,听上去就比较机械】我们的语音之所以听上去自然,应该也有”不对称“和不规律之美吧(虽然有大致的规律)
推荐大家使用adobe audition来观察语音。matlab也可以观察和处理语音
Q9 语音数学定义/FFT/数字化
问:语音(波形)是否存在一个数学定义?fft之后的结果和原始语音是否等价?
声的原始定义就是能够引起听觉的振动。 而fft只是把声音(包括语音)转换的频域里去观察,能够体现出很多特点来。两者不冲突。 以前图像也是要在频域里观察的,但是目前深度学习已经在图像上像素做输入了(神经网络取代了信号处理,或者说充当了信号处理的作用)。 声学的门类就很大了。我找一本基础的,稍后发一下。
数字化和 转频域是两个概念,数字化只是 采样、量化、编码。任何信号进入计算机都要做的事情。 频域是观察这些信号的手段。 模拟信号有信号处理,数字信号也有信号处理,是数字信号处理了(傅里叶变换也变成了离散傅里叶变换)
Q10 基音 vs 基频
基音的频率最低, 强度最大。基音的频率即基频。
Q11 鸡尾酒会问题(语音分离)
这个近两年的研究挺热的,要说具体进展怎么样,我也不好说,基于各种神经网络结构的说话人无关的语音分离,在MERL释放的基于WSJ的数据库上,那效果是很好,特别还有基于时域的TasNet,超过了很多频域的模型,但是这种有监督的学习都需要用仿真数据去训练,在实际测试的时候,数据由于受到噪声、录音设备、混响等影响,效果还不行。
现在大多数方法,可能还是基于深度聚类(deep cluster),置换不变性训练(permutation invariant training),TasNet,Deep attractor这些方法来的,有的还增加了多通道的数据,或者相位信息,但是大致方向应该就是这些(据我之前了解)
-
kaldi资料共享
——来自《语音识别:从入门到精通- 第一期》·84浏览
1.来自pelhans的kaldi脚本解读
http://pelhans.com/tags/#Kaldi
2.吴本谷(4届kaldi线下交流群组织者)大佬的博客
https://blog.csdn.net/wbgxx333/article/details/18516053
3.国外大佬的博客
https://www.eleanorchodroff.com/tutorial/kaldi/training-overview.html
4.一个非常基础,面向小白的专栏















