-
第八章作业点评
——来自《语音识别:从入门到精通- 第一期》·54浏览


-------------------------------------------------------------------------------------------------------
本章的学习讨论总结在以上链接上,大家如果有问题的话可以链接里面进行查看。
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
首先我们进行第一道题目的讲解。
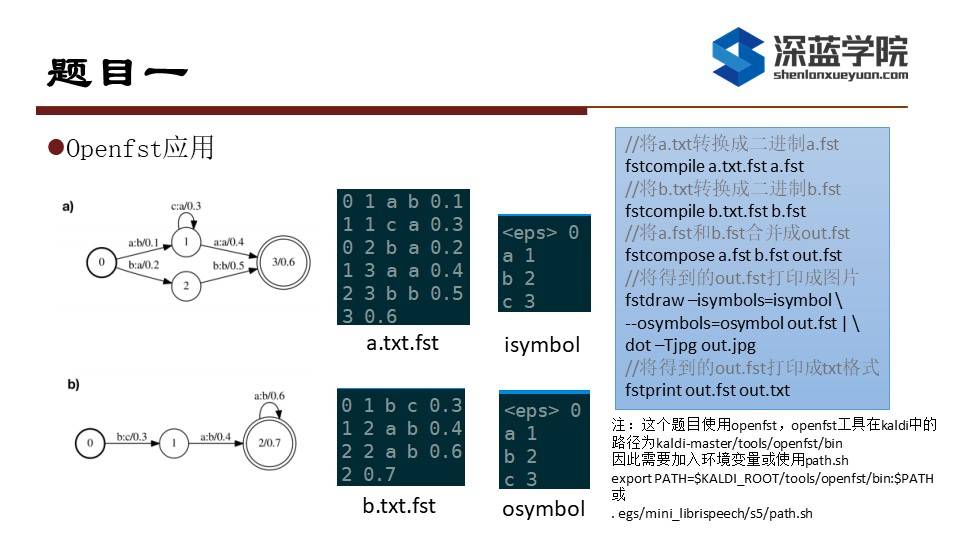
本章的作业我们注重实际动手操作,共有三道题目,首先是Openfst的应用题目,我们需要将a和b两个状态图写成openfst格式的文件。
首先我们看到fst文件里面的内容,每一行都代表一条边,第一列是出状态节点编号,第二列是入状态节点编号,第三列是输入标签,第四类是输出标签,五列是arc的weight。最后一行表示结束状态和结束状态的weight,做这个作业我们需要的是openfst工具,想要使用这个工具我们首先需要将工具中的可执行文件加入环境变量(PPT右下角的export指令)或者使用kaldi样例给的path.sh也可以。Fstcompile是将txt格式的fst定义转为二进制fst文件,fstcompose可以将两个二进制fst文件合并成一个fst文件,fstdraw配合dot可以将fst打印成图片,或者是使用fstprint可以将fst输出为txt格式,另外在使用fstdraw和fstprint时使用isymbol和osymbol可以将输入输出的id号转为更容易阅读的文字。
-------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------
下面是作业二的讲解。
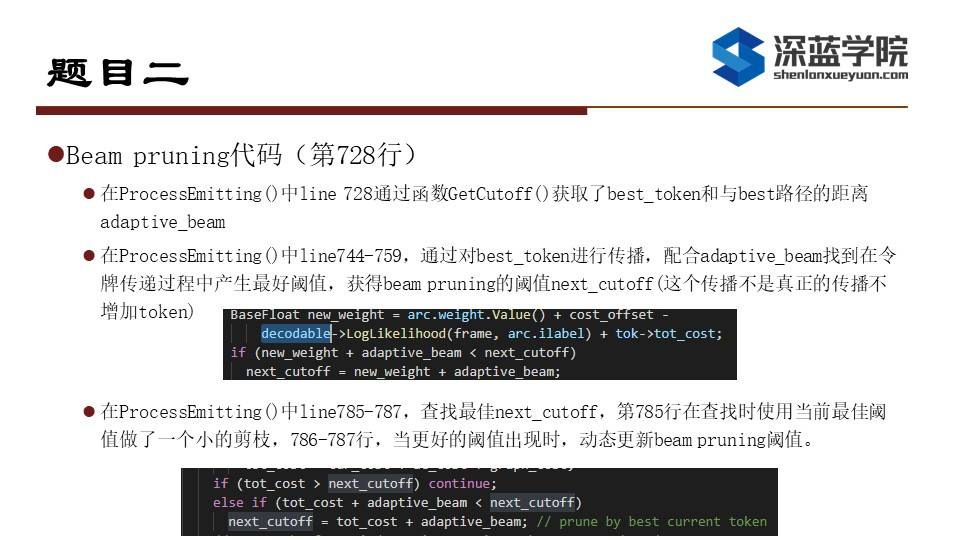
在作业二中我们要找到kaldi的两种剪枝方法,这两种剪枝方法主要在kaldi/src/decoder/lattice-faster-decoder.cc中的第728行ProcessEmitting(),首先看Histogram pruning,代码首先通过函数GetCutoff()获取histogram剪枝阈值,histogram通过限制最大和最小的active token数量来进行剪枝,这个主要体现在GetCutoff函数里,这个函数的逻辑是如果对于max_active和min_active没有限制则返回最小cost+beam作为剪枝阈值,如果max_active的cutoff比beam pruning的小则返回max_active的cutoff,如果min_active的cutoff比beam pruning的大则返回min_active的cutoff(histogram pruning)。大家可以看到这个函数的输入,第一个是token的指针,第二个是active token数量,第三个是beam的大小,第四个是包含cost最小token的Elem对象,这个Elem对象是包含token 的。最后判断token的cost和cur_cutoff值来完成histogram pruning。
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
再来看beam pruning,beam pruning主要是在token进行传递的过程中进行阈值计算以及剪枝的,首先对最佳路径进行了试探性的传播,可以注意到这个传播并不是真正的传播,不会增加实际的token。在这个传播中我们会计算出最佳的新阈值,之后对各个token进行遍历时同样也会计算最佳阈值进行更新,这里会对token cost做一个小剪枝,当token的cost大于当前最佳阈值时则跳过。
-------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------
最终在ProcessNoneemitting()中进行beam pruning,这个cutoff值就是刚刚计算的next_cutoff值,在这个函数中我们实际进行了令牌传递更新了tokens,因此在讨论区的一个问题beam pruning和histogram pruning有前后关系吗,事实上我们剪枝的阈值基于histogram pruning和beam pruning的共同作用,而这两个剪枝方法的特点就如同下面这句话所说,histogram pruning是这一帧处理完成了进行,作为下一帧的开始,而beam pruning是随着token产生进行处理的。
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
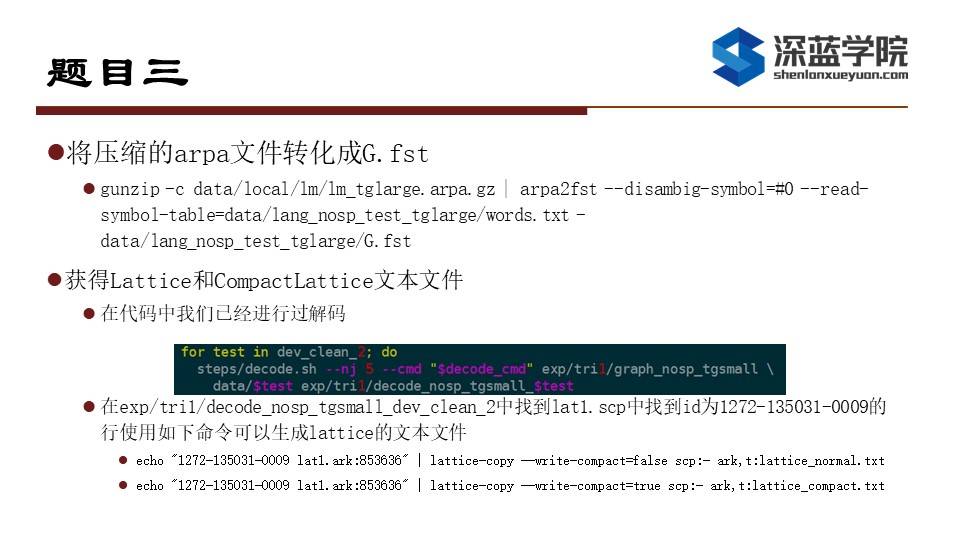
在题目三中我们将实际上手进行解码,我们首先使用mini_librispeech的run.sh进行下载、准备数据和训练到tri1,此时我们将data/local/lm中的arpa文件的压缩包解码并转换成G.fst,我们在转成成G.fst的时候使用arpa2fst转换成G.fst文件。接下来使用tri1模型和tgsmall构建的解码图进行解码产生lattice文件,指令就是steps/decode.sh。这个结果应该是在21-22之间。我们查看对应id的lattice可以用这种方法,首先我们echo出id和lattice对应的scp,通过通道符传给lattice-copy。这里scp:-就是把前面给到的通道输入到到lattice-copy,这样就可以找到id对应的lattice并且打印成txt文件。
-------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------
最后我们使用新的G.fst对原本的解码结果进行重打分,使用steps/lmrescore.sh工具,最后获得wer,可以使用kaldi提供的best_wer.sh获得不同lmwt和不同wip组合中的最佳wer作为我们最终的结果,如下图所示我得到的是lmwt为15,wip为0.0的wer结果。
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
QA
Q1:为什么cur_cutoff算的是 inf
A1:对于第一帧GetCutoff得到infinity是正常的,一般min_active_tokens会设置一个比较小的数值,比如20。如果你原本这一帧初始的准备处理的tokens比这个min_active还要小,就会返回infinity。 比如你的min_active=20,你这帧最开始只有10个tokens,那么这10个tokens都会被处理,这个cutoff=infinity。某一帧cur_cutoff==inf并没什么问题,这是正常的,代表不裁剪tokens,所有的都处理,不会导致程序崩溃。
-------------------------------------------------------------------------------------------------------

-
第七章作业讲评
——来自《语音识别:从入门到精通- 第一期》·44浏览

---------------------------------------------------------------------------------------------------------------------
本次作业主要分为两部分,第一部分是使用SRILM工具来完成语言模型的训练和PPL计算,第二部分是完成哥大E6870课程的作业,包括Ngram计数和Witten-Bell平滑实现。
---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
SRILM这个工具中Kaldi中也是有包括的,如果大家之前已经编译好Kaldi的话,那么在本次作业中就不需要重新下载。
另外大家如果对第七章学习中有疑问,可以先查阅下讨论区中学习委员总结的“第七章学习讨论总结”贴,这对大家解惑应该会有很大帮助。
---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
首先我们需要对数据做一些处理,由于我们下载的数据是包含uttid和抄本,实际上训练语言模型我们只需要抄本就可以了,我们可以利用Python或者Shell写一个脚本对文本做一下处理就好了。
第二部分就是利用ngram-count这个方法,通过传递处理好的训练文本和词典,来生成ARPA语言模型,这边给出的是一个参考实现,有一些地方可能不一样,但问题也不大。如果出现了UNK,这边实现上是把它映射成<SPOKEN_NOISE>。
最后就是计算PPL,只需要传入测试文本和语言模型就可以了。在作业中是要求利用KN平滑算法,但在使用过程中会报错,因为我们提供的文本数据集太小,有一些统计量并没有统计到。另外就是SRILM使用的KN平滑算法是改良过的,大家可以通过--help参数来使用原始的KN算法,看看是否会出现不一样的结果。在参考答案中我们使用的是Witten-Bell算法,在实际数据集中比较小的情况下一般都会使用这个算法。
---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
在作业的第二个部分需要实现的是Ngram计数和Witten-Bell平滑算法,在进行解释之前,我们来看一下可能会使用到的相关的类和方法。
---------------------------------------------------------------------------------------------------------------------
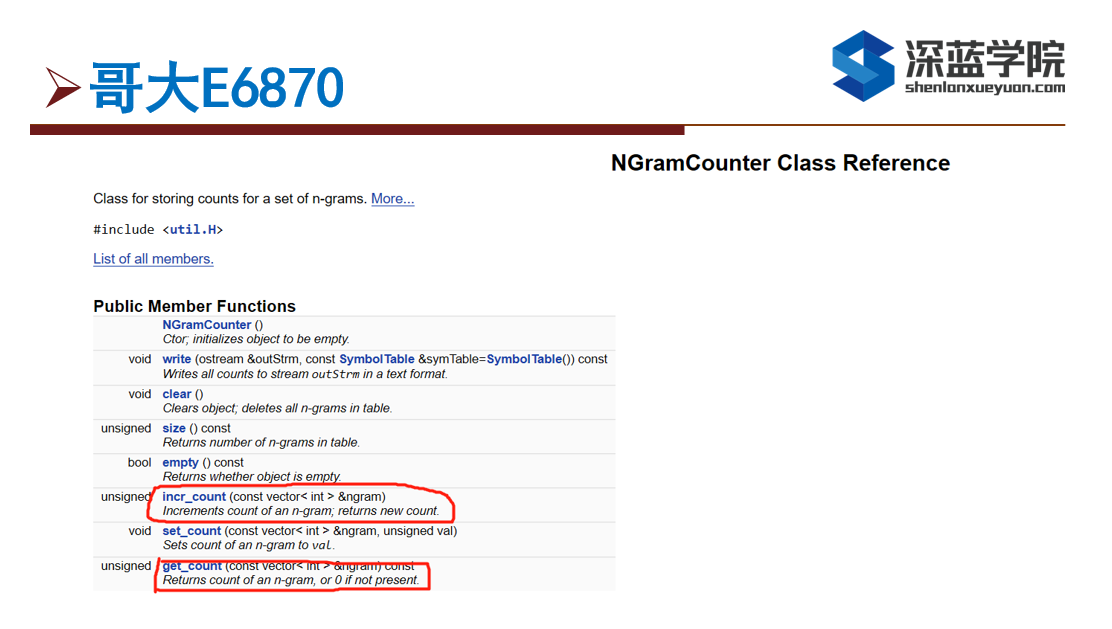
---------------------------------------------------------------------------------------------------------------------
在这次作业中主要是用到NGramCounter( )这个类中的incr_count( )和get_count( )两个方法,incr_count( )主要是用来计数,get_count( )用来获取给定vector的计数给取出来。
-------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------
首先我们会看到两个循环,在外层循环中表示wordid的vector(整个句子中所有的单词),在内层循环中主要是编辑计算从1到ngram的计数,譬如n=3的话,就要计算unigram、bigram和trigram三种计数。
在这题中我们会看到三种数据结构,以trigram(a, b, c)为例,首先要把abc的数量纪录下来,第二就是要纪录histNgram(ab)对应条目的数字,第三就是计算histOnePlusCounts,这块主要是后面Witten-Bell平滑实现中会用到的,填histOnePlusCounts的时候我们只需要去把前面的History如果有出现的话只需要加1就可以了。
-------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
第二部分就是实现Witten-Bell平滑算法,主要要计算MLE和回退的部分,譬如bigran回退的话就是回到unigram。在公式上我们可以看到c_h和N_(1+),分别代表的是history和historyoneplus,这些我们在前面都已经计算好了,因此我们只需要直接取来用就可以了。
---------------------------------------------------------------------------------------------------------------------
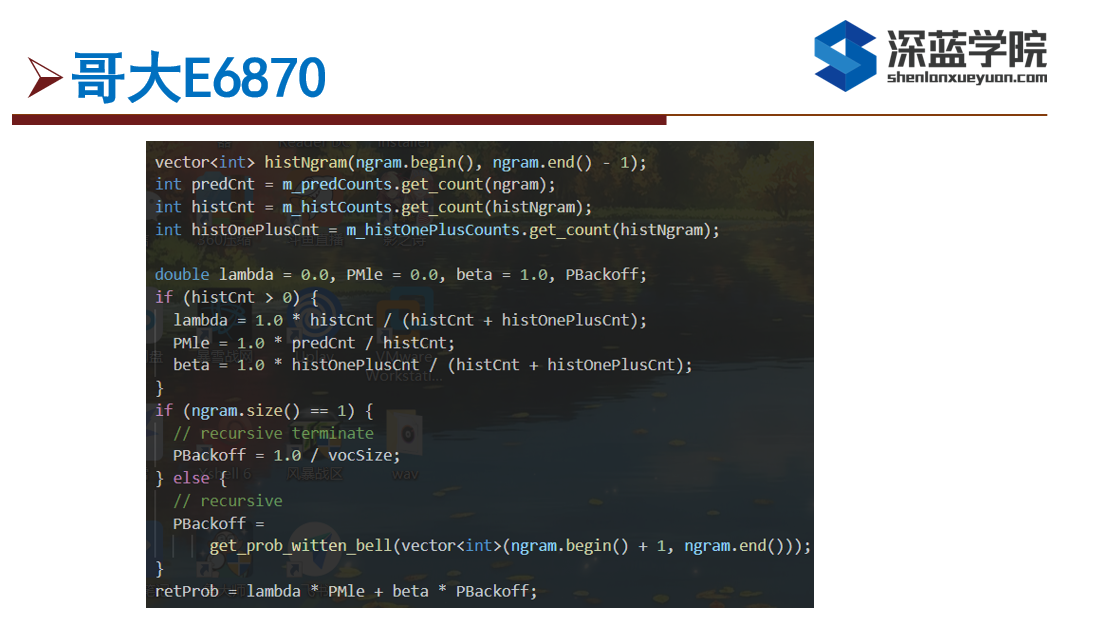
---------------------------------------------------------------------------------------------------------------------
代码实现中,我们只需要从之前统计好的那三个对象,去取所需要的Ngram的词相对应的统计量,然后根据公式去计算MLE和相对应的系数。在代码中,lambda对应的是MLE的系数,beta对应的是回退部分的系数。
另外我们可以看到虽然公式给的是bigram的例子,但其实用于更高阶的ngram一样都是可以通过递归的方法来实现的。
---------------------------------------------------------------------------------------------------------------------

-
第六章作业讲评
——来自《语音识别:从入门到精通- 第一期》·64浏览

---------------------------------------------------------------------------------------------------------------------------------------------------------
本次作业分为两个部分,第一部分是利用Python实现DNN算法,第二部分是利用公开的ASR中文数据集THCHS30,结合Kaldi这个工具去进行语音识别模型的训练,借此了解整个语音识别的流程。下面我们先来看第一部分。
---------------------------------------------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------------------------------------------
在DNN算法这部分作业中,我们需要实现RELU激活函数和全连接层的前后向算法,其中我们需要理解一下神经网络中的解析梯度以及求导的链式法则的实现原理。如果对以上原理不太理解的同学,可以参考 CS231课程的第4.1节和反向传播的内容,以上图片左边描述的就是一个反向传播的例子。
首先给定的函数是f(x, y, z) = (x + y)·z,通过链式法则,我们就可以求出输入x对于最后输出f的梯度。把同样的情况运用在全连接层上的话,在求出loss之后,给定损失函数,我们就可以算出输入对于输出的梯度,这样就可以获得参数的更新。
右边的代码就是RELU激活函数和全连接层的实现,其中关于RELU函数,如果是前向算法中,我们则需要求出max(input,0)就可以了,而在RELU的反向传播函数中,由于在小于0的时候是不存在梯度的,所以只需要在大于0的情况下直接返回d_output就可以了。
全连接的梯度更新中,dw的更新是把前一步传过来的d_output和input做一个点乘就可以了。update的函数中是一个简单的SGD优化器,再给定一个确定的学习率之后,只需要根据dw应用到w上就可以完成一次参数的更新。
---------------------------------------------------------------------------------------------------------------------------------------------------------
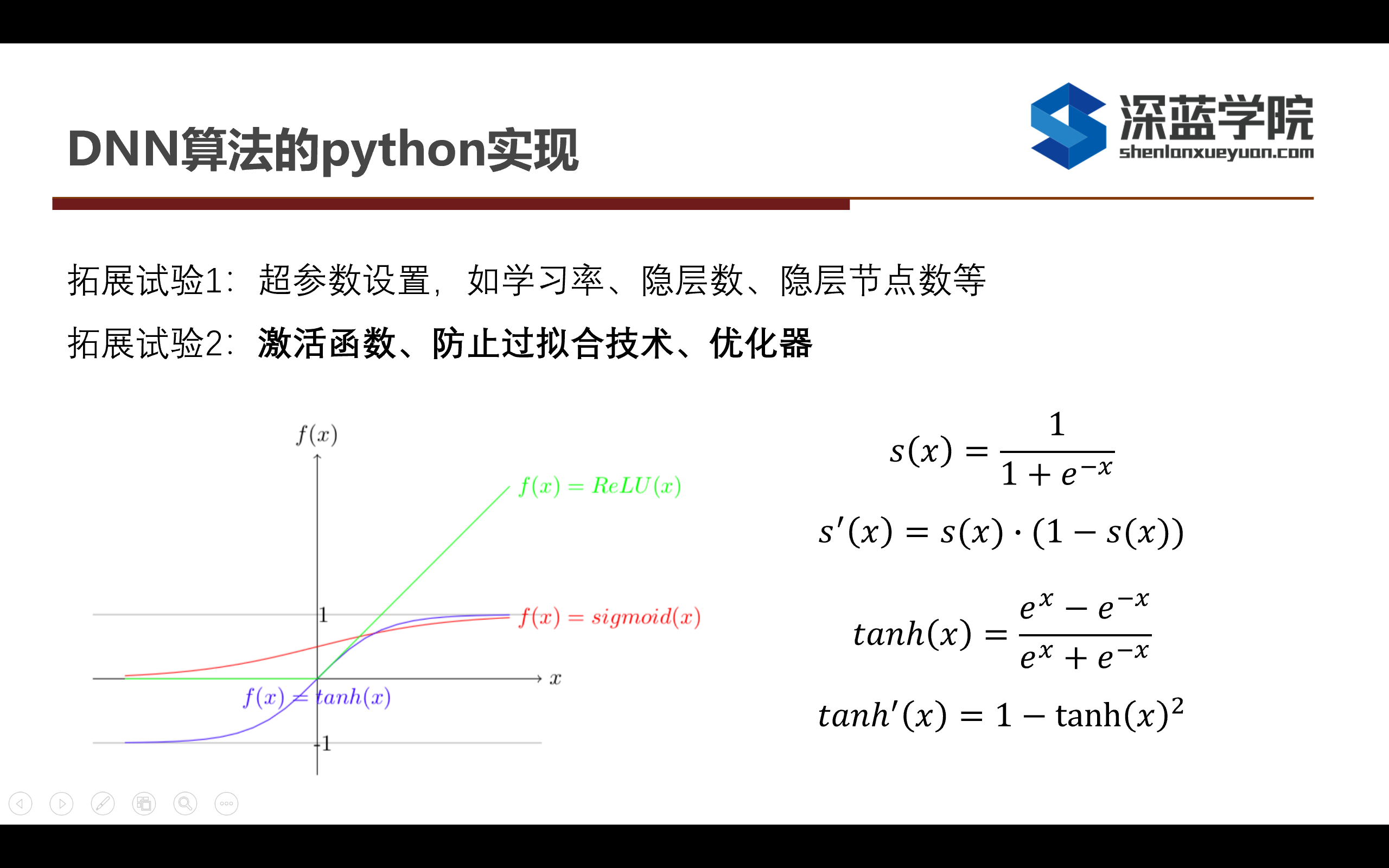
---------------------------------------------------------------------------------------------------------------------------------------------------------
关于sigmoid和tanh的前向反向算法公式在上述图片中描述出来,因此只需要根据对应的解析梯度的算法就可以计算出来对应的梯度。
---------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------------------------------
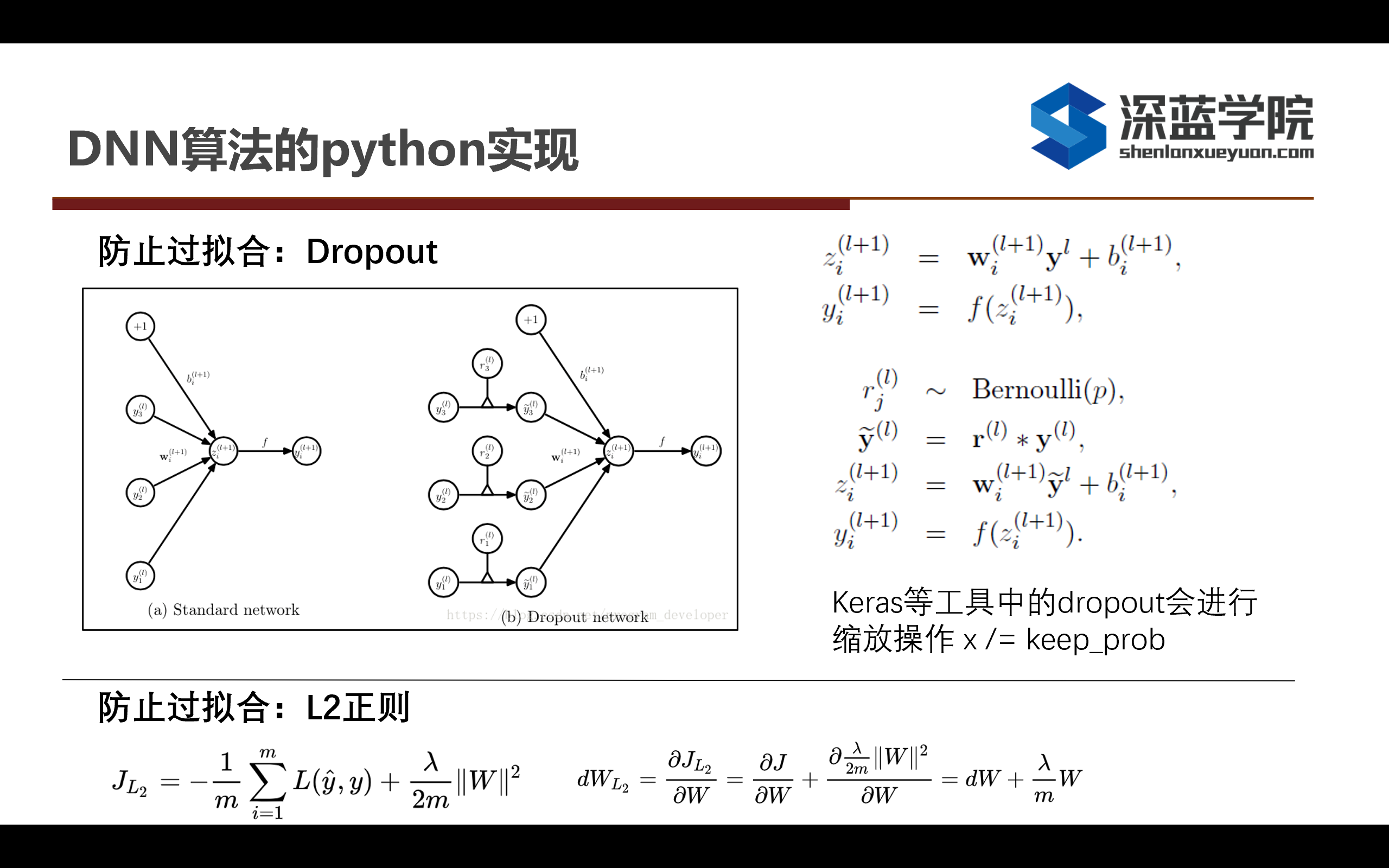
关于防止过拟合的Dropout和L2正则都是出现时间比较长并且被验证过能够比较防止网络过拟合的有效方法。首先来介绍第一个防止过拟合的算法是Dropout,从原理上来说按照一定比率使全连接层的某些神经元失效,在计算梯度的时候就不会去计算来自某些失效的神经元的梯度,根据dropout_rate来决定有多少比例的神经元是需要忽略对应的梯度的。值得注意的是,在Keras等工具中会对Dropou之后t进行缩放的操作,也就是x = x / (1 - dropout_rate),这样可以让整个神经网络中的梯度传播比较稳定。
关于L2正则中,考虑到在神经网络的更新过程中,可能会有一些过大的权值会导致网络不稳定,因此L2正则实际上是对神经网络的权值进行一个衰减,这样可以实现一个更加稳定的网络更新过程。
---------------------------------------------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------------------------------------------
第二部分的作业是让大家利用Kaldi跑一下THCHS30例程并且对当中的run.sh的每一个步骤做分析。
---------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------------------------------
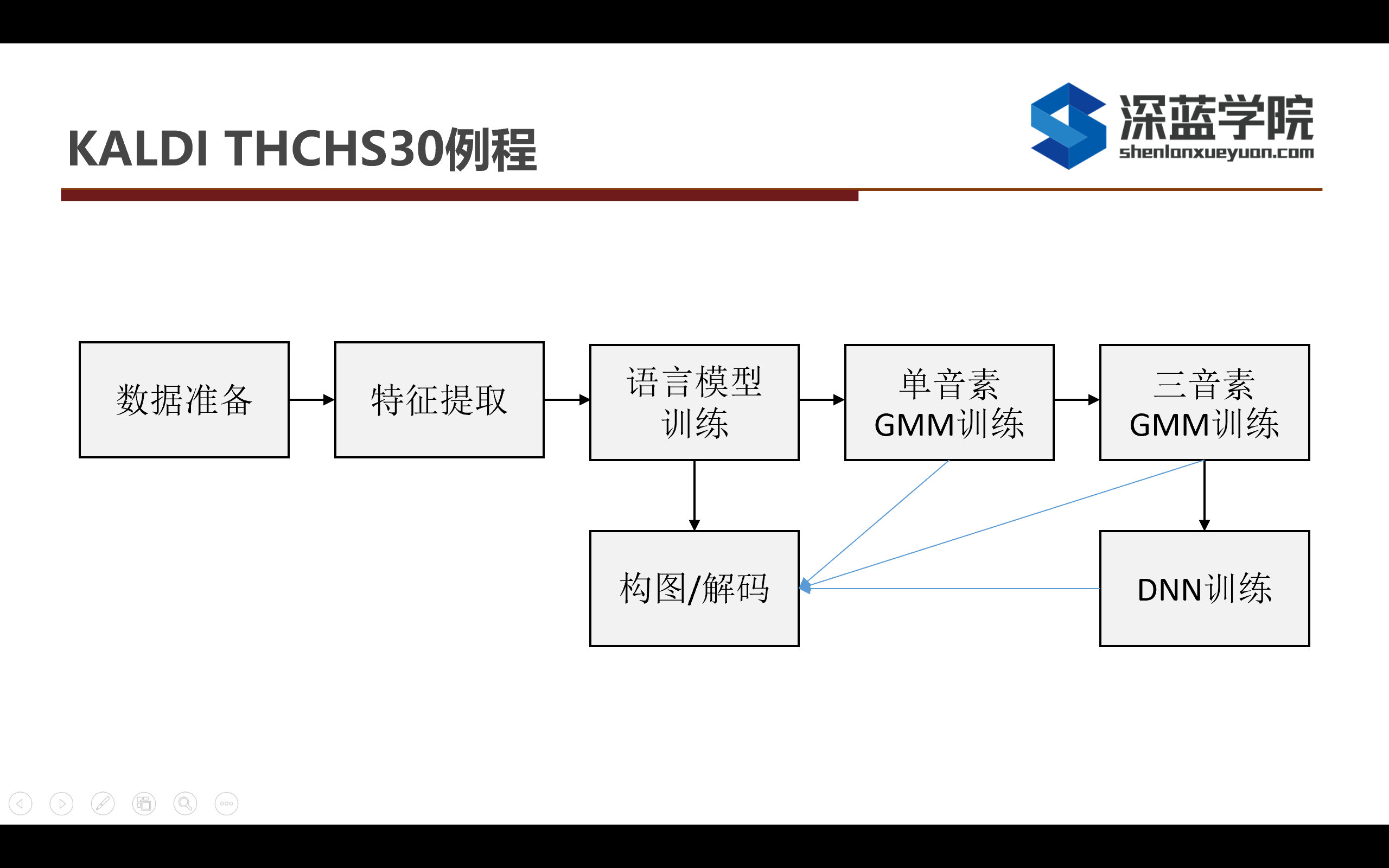
基本上Kaldi中所有的例程都是按照上述的流程进行ASR模型的训练的,它分为数据准备、特征提取、语言模型训练、训练单音素、三音素,然后根据三音素的对齐结果训练DNN,最后结合声学模型和语言模型结合HCLG图进行解码。
无论是三音素还是单音素,一步步迭代的目的都是为了得到更加准确的对齐结果,而如果得到比较好的对齐结果,这样会对后续的DNN训练会有很好的精度提升的帮助。
---------------------------------------------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------------------------------------------
在THCHS30的run.sh中,我们还看到了其他的方法,譬如SAT、LDA、FMLLR等,下面我来给大家做一个简单的介绍。
首先SAT全称是Speaker Adaptation Training,指的是说话人适应的训练,在训练中提取说话人的向量,在解码的时候通过相关操作排除掉跟说话人相关的信息,只保留语义相关的信息来帮助ASR的训练。
然后LDA和FMLLR都跟PCA分解比较相像,实际上都是在特征上做跟矩阵分解相关的工作,目的都是为了增大类间距,缩小类内值。关于FMLLR目的是在训练过程中通过提取一个说话人相关的向量,最后完成一个说话人无关的语音识别系统。
下面从四个方面跟大家介绍一下Kaldi这个工具,第一个是数据相关的,第二个是跟建模单元和拓扑结构相关的,第三个是跟Nnet神经网络相关的,最后一个是在训练模型或者准备数据中可能会用到的工具,下面我会对这四个方面做一个简单的介绍。
首先是第一部分跟数据相关的,text(抄本)、utt2spk(语音和说话人的映射关系)、wav.scp(音频的存放路径),还有像spk2utt和utt2dur等文件都是存储跟特征和抄本相关的信息。
第二部分是拓扑结构和建模单元大家可能会用到,比如说之前训练的都是三状态的HMM结构,那么现在想训练一个五状态或者七状态的结构,这个时候就可以修改一下topo这个文件。跟建模单元相关的,就可以看一下data/lang目录下面的phones.txt。如果想手动对部分音素进行绑定,譬如说针对部分出现频率较低的音素,就可以修改root.txt文件,来手动对音素或状态进行绑定。
第三部分是神经网络相关的,Kaldi是通过xconfig来生成整个神经网络的参数,然后它会调用Kaldi实现的一些网络层,大家可以依次来搭建自己需要的神经网络。
最后部分就是tools in utils and bin。大家在实际工程使用中可能会需要一些小工具,譬如将utt2speak转成speak2utt,类似于这样的小功能Kaldi已经帮我们实现了,所以我们自己不需要再重复实现,都可以在utils这个文件夹里面找到。譬如想提取特征的arc进行操作,或者是对alignment和lattice进行操作,我们都可以在bins这个文件夹中找到对应的方法,熟练使用这些小工具对于提升大家的使用Kaldi的效率是有很大的帮助。
---------------------------------------------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------------------------------------------
-
第五章作业讲评
——来自《语音识别:从入门到精通- 第一期》·62浏览


-------------------------------------------------------------------------------------------------------------------
这个作业其实是E6870课程的课后作业,在本次作业中我们需要完成三个部分的代码,第一部分是维特比算法,第二部分是利用维特比训练GMM-HMM模型,最后是完成前向后向训练算法。下面我们先看看整体的代码框架。
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
首先我们来看一下graph类,第一个核心函数是get_start_state( ),指出HMM这个graph的初始state,会以index的返回方式来指明是第几个state。第二个核心函数是get_arc_count( ),作用是拿到当前time的state后会有几个弧,而第三个核心函数是get_first_arc_id( ),作用是指明弧出去的第一条路的ID为多少。
然后上述框出来的代码部分就是遍历graph,首先通过get_arc_count( )获得总的弧数量,然后再通过get_first_arc_id( )获取到第一个arc 的ID,然后在for循环中根据弧的数量进行遍历,每次遍历的时候利用get_first_arc_id( )获取弧指向的state的index。
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
这一块是GmmSet,在这里核心的函数有四个,但我们只需要使用后面两个函数就可以了。第一部分是get_component_count( )和get_component_weigth( ),由于我们使用的是一维GMM,成分只有一个,因此在实际的代码中是用不到的。
后面get_gaussian_mean( )和get_gaussian_var( )是为了计算高斯分量的均值和方差,这部分函数在后续做EM训练的时候会用得到。
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
还有一个重要的函数是add_log_probs( ),在前向后向算法中会用到,作用是将取log后的概率相加。在源码实现中我们可以看到,它送进去一个取log对数的概率vector,然后利用exp函数恢复到取对数log之前的概率值,然后再加起来,最后对结果再做一次对数log操作。
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
下面我们来看第一部分维特比解码,实际上我们需要完成右边算法的第二部分Recusion,也就是计算v_t(j)和bt_t(j)。首先获取帧数frmCnt和stateCnt,然后按照帧数去做一个遍历。需要注意的是,在chart类里面是会自动对frmCnt+1,但对于gmmProbs里是不会对frmCnt作修改,还是保留原来的个数,所以大家对下标进行索引的时候需要注意一下。
首先看第一个红框,它表示对起始状态的处理。对于第一个起始状态start_state可以通过函数get_start_state( )获得,对于这一帧就不需要进行遍历,只需要对有效帧进行遍历即可,对于起始帧只需要做get_arc_count( )和get_first_arc_id( )操作即可。当start_state的frmIdx为0时表明在chart中只有这个starte中存在概率,因此概率为1,取log对数后就为0。
然后在进行遍历的时候,对当前的state去计算prob,也就是左边公式上第二部分的v_(t-1)a_(ij)b_j(o_t)。对应到左边代码的就是计算logprob。v_(t-1)对应的就是代码中的chart部分,b_j(o_t)对应的就是gmmProbs,而a_(ij)对应的就是arc.get_log_prob( )这条弧上的概率部分。
然后代码下面的if代码就是max部分的操作。如果在当前state算出来的logProb大于dstState中的v_t(j)概率,那么就需要对dstState中的概率进行替换。对于argmax部分,每次在进入遍历弧上所有的状态之前,需要把当前的arcId存在curArcId变量上,那么在解码的时候我们就可以知道当前的最大概率是从上一个timestep的哪个state过来的。
需要注意的是,这边的logProb大家最好取成double类型,答案应该是跟ref一模一样的,如果是取float的话,结果的小数点后几位应该会和ref对比会有一些差别。
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
下面进入第二部分维特比训练,根据维特比decode得出来的路径进行GMM的优化,而主要需要完成的内容是EM算法,也就是算法9.2部分。第一部分就是add_gmm_count,去计算m_gaussCounts里面的m_gaussStats1和m_gaussState2。
这里需要完成的每一部分都用红线跟右边的算法做对应。值得注意的是posterior放在m_gasussCounts里面,是因为GMM只有一个分量,因此在E步的gamma_jk都是1。因此分母的计算就是直接有多少个1就直接加起来就可以了,分子部分分别计算gamma_yhat和gamma_yhat的平方就可以了。然后需要一个for循环把每一个维度的feats特征去乘以posterior(也就是gamma_jk)
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
下面我们就是需要做EM算法中的M部分,分别去更新均值和方差。在更新均值部分,我们利用前面算好的m_gaussStas1除以m_gaussCounts。方差更新的逻辑也跟更新均值一样,需要注意的是把方差计算中的完全平方项展开,计算完之后利用set_gaussian_mean和set_gaussian_var对均值和方差进行更新。
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
第三部分就是完成前向后向训练,前向部分如右边的公式所示,我们主要是完成第二部分Recursion,这部分跟前面维特比解码是很相似的,有区别的两部分就是logProb的计算以及如何加起来。计算logProb部分则由三个部分组成,分别是alpha_(t-1)(i)、a_ij和b_j(o_t),分别对应代码中的chart(frmIdx, stateIdx).get_forw_log_prob( )、arc.get_log_prob( )和gmmProbs。需要注意的是下标,如果下标错了的话结果就会比较离谱。最后通过add_log_probs将概率给加起来,代码实现上即可以像这边定义一个vector然后通过初始化的方式来实现,或者定义vector然后通过push back的方式也是可以。
-------------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------------
至于反向部分,大家可以参考一下代码的实现,这块代码的第二部分需要完成的是前向后向的E步的计算,也就是xi(i, j)的计算。这块部分概率的计算跟之前的计算都很相似,首先对每一帧和每一个state进行遍历,然后计算分子部分,分别是alpha_t(i)、a_ij、b_j(o_t+1)和beta_(t+1)(j)分别代表的是计算好的前向概率chart(frmIdx, stateIdx).get_forw_log_prob( )、弧上的概率arc.get_log_prob( )、gmmProbs(frmIdx, gmmIndex)以及计算好的后向概率chart(frmIdx + 1, dstState).get_back_log_prob( )。
然后除以分母部分,相当于对数计算中的减法。然后把结果取exp指数得到真实的概率,然后再push back到gmmCountList中以备后面做EM算法使用。至于uttLogProb表示的是当前utt的最后一帧的前向概率作为整句话的logProb,所以我们在计算的时候直接取出来代进去就可以了。
-------------------------------------------------------------------------------------------------------------------
|课堂问题
Q1: 在double forward_backward( )函数中初始状态assign里这个-1是什么?
A1: 这个第二个参数arcId指的是这一帧的这一state所获取的最大prob的来源state,对于初始state来说,它没有来源,所以就用-1替代。
-------------------------------------------------------------------------------------------------------------------

-
第四章作业讲评
——来自《语音识别:从入门到精通- 第一期》·39浏览
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------
前两道题如何,使用Python编程实现前向算法和后向算法,分别去计算在已知参数的情况下获得该观察序列的概率。
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------


------------------------------------------------------------------------------------------------------------------------------------------------------
代码基本上是按照公式进行书写。以前向概率为例,第一个循环为初值的计算,第二个三重循环则为递推计算的实现部分,算法是和公式一一对应。最后一个循环则是终止部分,也就是将最后一个时刻的前向概率求和。
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------
下面就是维特比算法作业的讲解。
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------
我们来看初始化,也就是在时刻t=1时,对每一个状态i(i=1,2,3),求状态为i观测o1为红的概率,记此概率为delta_1(i)。
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------
第二步则为递推部分,也就是说在时刻t等于2的时候对每个状态i,求在时刻t=1状态为j,观测为红并在t=2时状态为i,观测o_2为白的路径的最大概率。看到这个公式我们很容易联想到前面的求前向概率的公式,只不过在这里时我们是取最大概率,路径是取最大概率的路径。
同时,对于每一个状态i,我们都需要去记录概率最大路径的前一个状态。之后我们会用回溯的方法会把整个状态给计算出来。
举个例子,在delta_2(1)的计算中,在0.1*0.5中,0.1表示在时刻t=1,状态为1下观测o_1为红的概率,0.5表示时刻t=1状态1跳转到状态1自身的转移概率,以此类推,然后我们会在这三个值中取一个最大值。而后面的0.5表示时刻t=2,在状态为1的时候观测o_2为白的概率,通过计算我们得到0.028。
同时对每个状态,我们去记录概率最大路径的前一个状态,在这里我们得到的都是状态3。
按照这个方法我们依次递推到最后一个时刻,得到最优路径的概率,并且得到了最优路径的终点,然后我们通过回溯的方法得到概率最大的状态序列。
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------
接下来我们对比一下代码和公式,代码是完全按照公式来书写的。第一个循环则为初始化过程,第二个三重循环表示的是递推的过程,中间是概率动态规划的计算过程,保留每一次取得概率最大的路径。最后一个循环就是最优路径的回溯。
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------
|课堂问题
Q1: 为什么训练三音素之前, 要先训练单音素? 直接训练三音素会有什么问题么?
A1: 三音素训练依赖决策树,决策树的生成依赖单音素的对齐,所以要先训练单音素
Q2: 状态级的对齐是如何用在决策树中的呢? 帮决策树提供了什么信息呢?
A2: 决策树聚类的单元就是三音素状态,目的也是为了减少三音素的独立的状态数
Q3: 所以叶子对应的gmm就是中心phone的gmm在不同条件(不同的左右phone)下的gmm,是吗?
A3: 一个叶子,可能绑定了几个三音素状态,他们共享一个gmm
Q4: 几个三音素的状态可以这么理解吗, 当我在解码的时候,我看到音素A,然后去以A中心的三音素的决策树,从根节点通过回答不同的问题,走到叶子节点,这个叶子结点所对应的GMM就是我要用来求发射概率的GMM?所以这样看来,一棵决策树的所有叶子结点都是中心的音素的GMM,只不过context相关的。如果没有这个决策树,那么会变成不管这个音素左右是什么都只对应一个GMM
A4: 如果没有决策树的话,一个三音素状态将会对应一个GMM,和左右有关,这可能导致GMM的数量是音素数量的三次方,所以提出了决策树的状态绑定,多个三音素共享一个GMM。
------------------------------------------------------------------------------------------------------------------------------------------------------

------------------------------------------------------------------------------------------------------------------------------------------------------
-
第二章作业讲评
——来自《语音识别:从入门到精通- 第一期》·53浏览
---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
至于具体实现部分,除了今天我分享的这些之外,我建议大家去看一下像Kaldi和librosa这些工具中的特征提取流程实现。
---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
那接下来我就具体讲解一下我们这次作业。本次作业中给出了代码的框架,我们主要做的部分就是设计滤波器和DCT变换这两部分。
---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
这次作业基本上没有太大的问题,只是大家的一些实现细节上会不一样。由于实际上用的时候基本上可能都会用工具,所以只要保证训练测试的时候提特征的流程一致就可以了。
在设计滤波器部分,需要设计它的刻度。在作业里面,对于16K的音频,频率可以取到8K。而由于采用的是梅尔滤波器,所以需要把刻度转到梅尔尺度上。
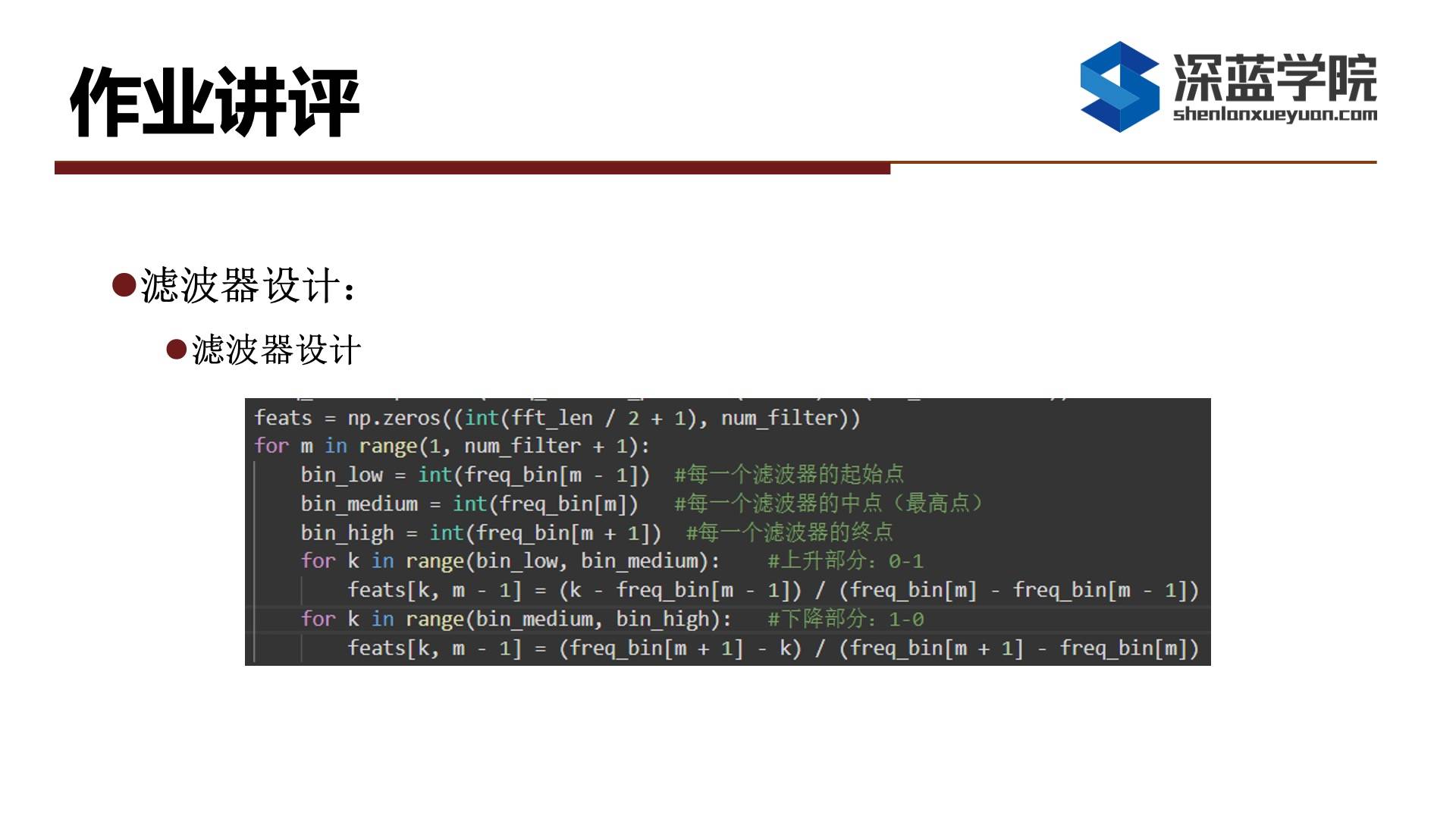
high_freq_mel = 2596 * np.log10(1 + (fs / 2) / 700) # 转到梅尔尺度上在转到了梅尔空间上后,需要在梅尔尺度上采点。譬如如果给定12个滤波器,那么每个滤波器的话就有三个点,分别是起始点、中间点和终止点。需要注意的是后一个滤波器的起始点和前一个滤波器的终止点是重叠的,所以我们在整个空间上一共需要取12 + 2共14个点。
mel_filters_points = np.linspace(low_mel_freq, high_mel_freq, num_filter + 2) # 梅尔空间中线性取点由于FFT得到的频谱是在线性空间上,所以我们在取点结束后需要转回到线性空间上。
freq_filters_points = 700 * np.power(10., (mel_filters_points / 2595) - 1) # 转回到线性谱最后一行代码,需要把频率0~8000部分缩放到FFT的窗长上。假设某个点取频率6000,但是FFT窗长只有512/2+1,因此是没办法对应上。因此需要把频率缩放到FFT的窗长这个新的横坐标上。
freq_bin = np.floor(freq_filters_points / (fs / 2) * (fft_len / 2 + 1)) # 将原本的频率对应值缩放到FFT窗长上---------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------
在滤波器的设计中,我们之前已经得到了一组点,其中每三个点对应一个滤波器,在这里我们需要设计滤波器的值。在该三角滤波器中中间点为最高点,表示为1,完全通过,譬如对于输入值而言,它乘上1表示值并没有发生变化,也就是说该输入值并没有经过过滤,如果在上升部分0-1做线性取值,如果取值为0.5那么输入值就会乘0.5,意味着原来输入的一半的值被过滤掉。
---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------
在滤波器设计完成后,就可以对FFT得到的频谱进行滤波,然后取log。
---------------------------------------------------------------------------------------------------------------------

-
精华 第三章作业讲评
——来自《语音识别:从入门到精通- 第一期》·58浏览
第三章作业讲评图文说明

本次作业要求我们使用em算法建立一个gmm模型用来做单个字符的识别,而这次作业的优秀评价标准为准确率大于97%,经过检查代码也没有问题。

在这次作业中我们一共要完成两个函数,其中第一个是计算对数似然函数,我们用ppt中的公式七,第二个是使用em算法更新参数,更新参数的公式是课程ppt开始的一页给出的公式。

本次作业完成较好,有较多优秀作业,这里展示一种大部分人都在使用的实现方法,首先是计算似然函数,这里这份代码最终取了平均值,公式里并没有要求取平均值不过并不影响我们最终的效果。

在进行em算法迭代时首先计算gama矩阵,之后是对参数的更新,这里建议最外层循环是对k的循环,这样比最外层为n循环减少了循环次数。

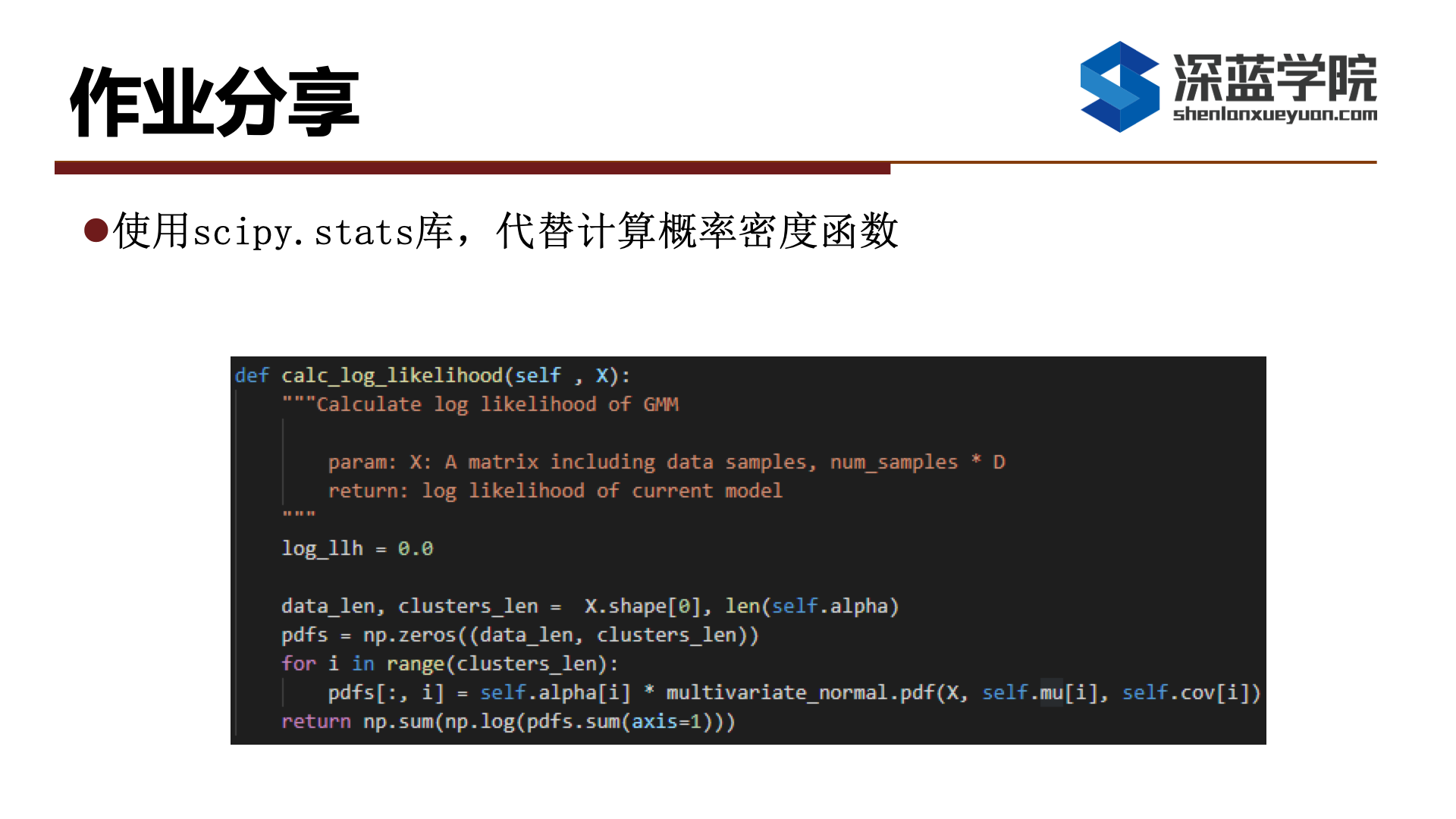
除此以外,也有同学使用scipy库里的函数代替代码给出的混合高斯计算概率密度函数大家可以了解、学习一下。

感谢阅读!















