-
我的录音真的有一模一样的话.....anyway,明白就好
-
37:05你可以听两遍。
对的。katz平滑算法会结合good-turing算法使用,对于高阶存在的时候,你用good-turing打折,这里讲的就是这回事。你把它理解成"打折率*P_ml"和"调整计数/N"都可以,两者等价。这里dr把分母的r去掉就是调整计数。
-
第五章GMM-HMM建模粒度问题
——来自《语音识别:从入门到精通- 第一期》·19浏览
HMM状态数是可变的,也不一定每一个都一样长,对于长的发音你可以用长一点的状态数。
我以前在英语phone上做过实验,根据统计,做一些变长,某些音素状态多,当然没有你这个小米的例子这么差别大。有一点点效果,但是不很大。
再举个例子,不同工具包对于不同音素定义长度也不一定一样。以前HTK,可能sil这种静音音素就用1个状态;Kaldi就用了5状态。
-
hmm中Zj的集合怎么得来的
——来自《语音识别:从入门到精通- 第一期》·30浏览
开拓老师讲的Viterbi学习算法,就是我说的Embedding Training。在“关于使用hmm进行孤立词识别的问题”我给的例子回答了这个问题。
每个HMM状态j对应的观测集合,就是你通过viterbi算法,获得隐状态序列 I=(i1,i2,...,iT)后,从O = (o1,o2,...oT)中抽取 {t | it=qj}所对应的所有ot。每一个是一帧MFCC。
-
observation都是每一帧MFCC特征。
对于HMM,你要理解它的建模单元,即一个从左到右的N状态HMM表示的是什么。对于孤立词,每个word对应一个HMM;对于单因素,每个音素(e.g. a)对应一个HMM;对于三音素,每个三因素(e.g. a+b-c)对应一个HMM。
-
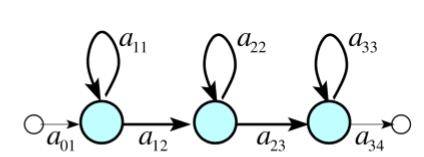
我不能理解你的问题。上图展示的就是一个HMM,它对应你的一个建模单元(i.e. word,phone,tri-phone),三个淡蓝色的圆就表示该HMM的三个状态。
-
并不是,通常你会有语言模型和字典。语言模型描述了word之间转移的概率,字典描述了一个word对应的一种或几种音素串。假设你的建模单元是phone。想象你有一个句子标注(i.e. word sequence), 这样你可以根据LM的概率指导word之间转移概率。之后word内部,你根据vocabulary扩展,如果只有一条路径,你建模单元phone之间的转移概率为1,如果多音字,转移概率通常会是统计出来的,进入下一个建模单元phone的概率。
-
由于spectral tilt(也称为声谱斜移)现象,低频的能量比高频的能量高一些,在语音识别里,预加重高频端的能量可以使模型能更好的建模高频信息。公式是y(n)=x(n)-ax(n-1),通常a取(0.9,1)。当a特别小的时候高频能量提升不明显。你可以自己画一个sound pressure level的图感受一下,变换后高频的能量会明显提升(比如从-40dB/Hz到-10dB/Hz,这只是个例子)
-
1. 这段程序,你首先获得了startstate,然后你应该遍历所有从startstate出去的arc。第二句应该是获得某一个从startstate出去的epsilon arc的id,不一定确定对应蓝色的那一条,可能是蓝色的那一条,取决于你graph的存储。遍历是合理操作,一定有某个arcId对应你图中蓝色。
2. 这张图上面每一条弧都是一个arc。
-
关于语音数据
——来自《语音识别:从入门到精通- 第一期》·31浏览
对于gmm-hmm训练你可以认为是无监督的。为了解释方便,这里我假定你HMM的建模单元是phone,你有lexicon(i.e. 你知道word与phone sequence的对应关系)。假设你没有抄本,你可以想象,你第一帧会到所有word的第一个状态,换句话说所有HMM的初状态,之后你每一帧会根据HMM进行跳转,也就是说,你每一帧大概都要计算到所有音素的各个状态。但是,加入你有抄本(i.e. 语音数据标注),你就可以对状态进行限定,你第一帧走的不再是任意状态,而变成了抄本里第一个词对应第一个音素的第一个状态,这样大大缩小了你的搜索空间。
此外,目前训练策略较多采用embedding training,这里生成一个强制对其。而且,你dnn获取强制对齐也是需要抄本的,你可以根据抄本,获得一条或者很窄的一束将phone level HMM进行连接的HMM链。这样你在上面用viterbi解码获得强制对齐结果。对于强制对齐,如果你没有抄本,只是用viterbi进行解码,可能你获得的是一个错误的对齐(e.g. 你把"It's a word"对齐成了"Eats a world"),这样你后面的训练也会跟着错。
-
关于使用hmm进行孤立词识别的问题
——来自《语音识别:从入门到精通- 第一期》·80浏览
“这个地方使用三个状态的hmm来代表每个单词,每个状态代表的什么呢?”
首先我们应该明确HMM的建模单元和状态个数实际是可变的。在这里,建模单元是word,然而你把word拆开成音素,对音素建模也是可以的。通常你到底选择怎样的建模单元要看你的任务难度,语料数据量等音素。这里十个数字差异性比较大,你HMM建模的颗粒就可以比较大。 状态个数这里取3个,你取4,5个也是可以的,3个有效状态通常是语音识别里面建模一个音素的习惯。
整体的来看,一个HMM建模了你建模单元(i.e. 在这里是一个word)的发音过程。如果你非要说每个状态对应什么,这是没有确定结论的,就像状态个数也是个超参数可以改变。如果一定要一个形象的概念,你可以这么感觉,第一个状态就像气流发音在胸腔,第二个状态就像气流在喉部,第三个状态就像气流在口腔,但注意我们只能说这是一个形象的揣测过程,并不是一个一一对应的确定关系。
训练的时候每个状态所对应的观测状态(mfcc)又是怎么来决定(难道是每个单词的wav文件三等份,然后求mfcc,在给对应的观测状态吗)?
注意,你提取MFCC的时候要考虑到语音的短时平稳性,通常我们我们会选25ms的窗长,10ms的帧移来提取MFCC。比如说1s的音频,你会获得100帧。假设你知道这1s的音频对应的是数字one,那么你就用这100帧mfcc数据来训练one对应的HMM模型。训练方法就是之前讲过的forward-backward和EM算法,或者开拓老师讲的时候提到的embedding training来更新模型参数。[简单的帮你回顾一下embedding training,它把这100帧强制对应到了某个状态,比如1-40对应第一个状态,41-75对应第二个状态,76-100对应第三个状态。之后你用对应帧的mfcc参数更新对应大GMM模型就可以了]
-
关于使用hmm进行孤立词识别的问题
——来自《语音识别:从入门到精通- 第一期》·80浏览
forward-backward和EM算法,讲的时候都是隐状态和观测是一对一的,但是如果分帧之后,隐状态和观测不是一一对应的,这个具体怎么处理?
在这里,我觉得你并没有理解隐状态和HMM每个状态区别。举个例子,在你学HMM那一章,应该讲了如下概念,隐状态序列 I=(i1,i2,...,iT)和观测序列 O=(o1,o2,...,oT),两者等长,一一对应。HMM的每一状态形成一个集合 Q={q1,q2,...,qN}。N与T无关。这里的隐状态描述的是某一时刻你处在某一个HMM状态上,就如你在转移矩阵定义里看到的 aij = P(it+1 = qj | it = qi),这里it = qi描述的是你第t时刻处于HMM状态qi。
如果按照emedding traning(我没有在开拓老师讲的视频找到这部分内容),首先怎么确定哪些观测对应到同一状态,比如怎么知道1-40是对应第一状态,而不是1-10? 第二个问题,使用这40个观测如何更新hmm,比如我们使用Viterbi学习(因为视频中讲都是一个观测状态的时候如何更新参数)?
【这里1-40只是例子,1-10也是可能的。】对于embedding training,你先有了这100帧数据对应的标注抄本。比如你的抄本是单词'he',你HMM的建模单元是monophone(HH IY),那么你可以感觉字典把he展开成一个HMM链,即 HH_state1->HH_state2->HH_state3->IY_state1->IY_state2->IY_state3,这里每个state都有自环,当你训练好了模型,你拥有转移矩阵和每个状态对应的概率密度函数(i.e. 发射矩阵)。你在这个HMM链上进行viterbi解码,你可以获得每一帧对应到哪个HMM状态。换句话,你获得了隐状态序列。
至此,你知道有隐状态序列 I=(i1,i2,...,iT) [每个it对应HMM一个状态] 和观测序列 O=(o1,o2,...,oT) [每个ot对应一帧MFCC]。你自然可以用MLE方法更新每个状态的概率密度函数和HMM的转移矩阵。 -
没有特殊含义,如果你愿意A+B-C在HTK里面也这么写。对于三因素,你应该留心它的中心音素,上下文context,而不单纯是记号。
-
数字串识别解码图
——来自《语音识别:从入门到精通- 第一期》·55浏览
我们设最左边的一个状态为初始状态,最右边两个圈的状态为wfst的final状态,中间三列为各个数字从左到右的HMM结构。每有一帧MFCC特征到来,会沿着箭头跳转(可能自跳转,也可能前跳转,注意某些结点没有自跳),每一次跳转都伴随着转移概率和可能伴随的(实际存在epsilon_arc)发射概率(不同的MFCC导致发射概率不同)的计算。不会一直停留在在最后一个状态。
此外,我建议你把这个图理解为示意图,不要完全的当成wfst,它的arc上没有记号,所以具体发生的是epsilon这种无需任何输入的跳转,还是会消耗一帧mfcc的跳转是不定的。[viterbi search的具体实现通常会用到token passing算法,你可以简单了解一下。]
-
关于音素的训练和解码
——来自《语音识别:从入门到精通- 第一期》·72浏览
概括的讲,实际上连续语音识别,你会有一个语言模型,它建模P(w_now | w_history),这个概率确实很多,是统计出来的;然后你有一个字典,它做word和phone sequence之间的映射。再结合你现在了解的对每个phone建模的HMM,你可以把每一个word展开成HMM状态上的链接。你可以借助下图理解:
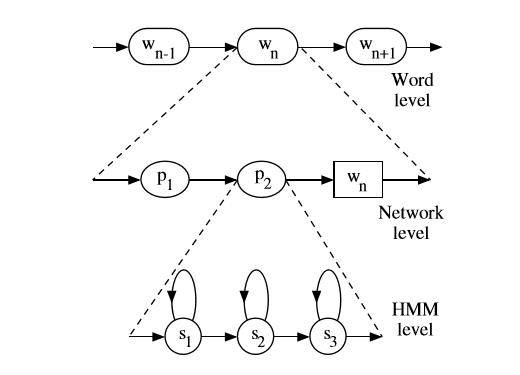
通常具体实现中,会给每一个3状态的HMM的头尾添加一个没有发射概率切没有自跳的状态,方便phone之间的链接(当然不同工具包不一样,HTK是头尾都加,kaldi你可以理解为只有在尾部添加),这主要取决于实现者。这个彬彬应该在课程里提了。
假设,类似kaldi,我们每个HMM有一个final状态,从音素的第三个状态跳转到final就是一个HMM内部问题,然后从final状态跳转到下一个音素的第一状态,普遍上概率为1,但是有时有多音字情况。这样我们就解决了word内部HMM的跳转。
对于word之间的跳转是由语言模型上的概率决定的,这确实很多。当然这里在实现上还有很多技巧,否则你从一个word理论上可以到字典上任意一个word(可能有成千上万), 一般会用比如phone-level prefix tree等方法来处理,等等。
-
关于音素的训练和解码
——来自《语音识别:从入门到精通- 第一期》·72浏览
“然后这个状态跳到下一个音素(无论是哪个音素)的第一个状态的概率都认为是1”
这个准确的说,是因为在一个word内,根据字典,你已经明确的知道了下一个phone是什么,所以这一步的跳转概率为1。但是比如一个字有多种发音则只是概率和为1(比如word1的发音为"a b c"或“a d c", 那么从a的final状态跳转出去到b或者d,只是概率和为1,分别的概率通常基于统计).
-
关于音素的训练和解码
——来自《语音识别:从入门到精通- 第一期》·72浏览
在词内,比如你有一个字'好(h ao3)',你对音素建模h和ao分别有自己的HMM,在'好'这个字内,你自然是知道从h的最后一个状态跳转到ao3的第一个状态。
在词间的时候,是由语言模型决定的,比如'好'可以跳转到'人(r en2)'这个字的第一个音素'r'的第一个状态,到'事(sh i4)'这个字的第一个音素'sh'的第一个状态等。当你处在'好'的最后一个音素'ao3'的最后一个状态后,你确实存在要跳到很多字的第一个状态的可能,理想化的可一个是vocabulary的任意一个字,当然prefix-tree等方法会进行一定处理(就像你说的简化跳转到每一个音素)。
对于LVCSR来说,解码图的确很大。识别时候,你可以想象成你先有一个word级别的跳转关系,然后每个word可以根据字典展开成hmm链。















