-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题 1:
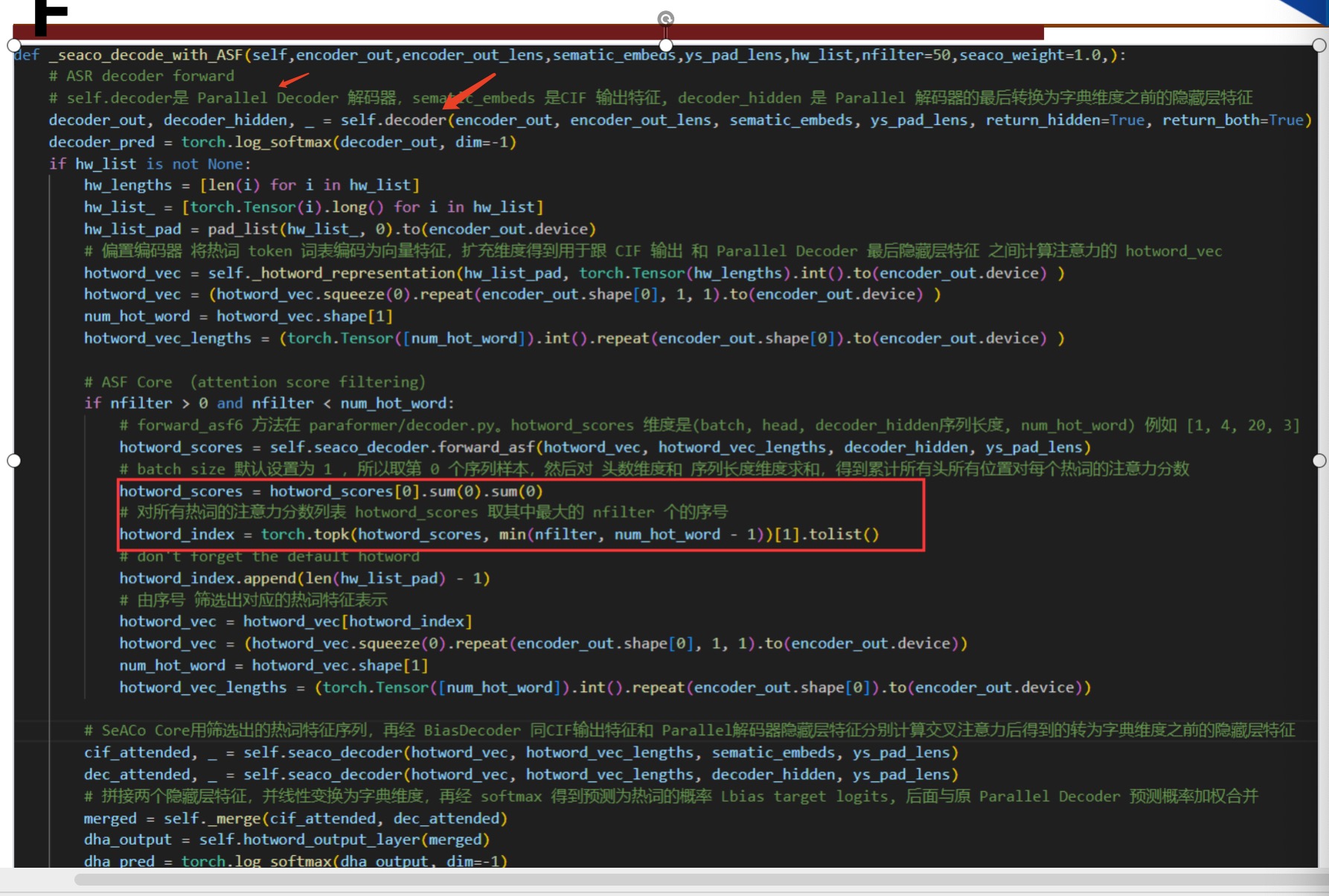
问:跟热词计算交叉注意力,这里为啥不用解码器返回的decoder out ,而 用decoder hidden?
答:decoder out 是每个位置最终输出的向量,已经是预测为词典中每一个可能的分数了,维度是词典大小很大,而 decoder hidden 是还没做最终线性变换的 512 维度压缩语义信息比较小更适合计算注意力关系。
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题2:
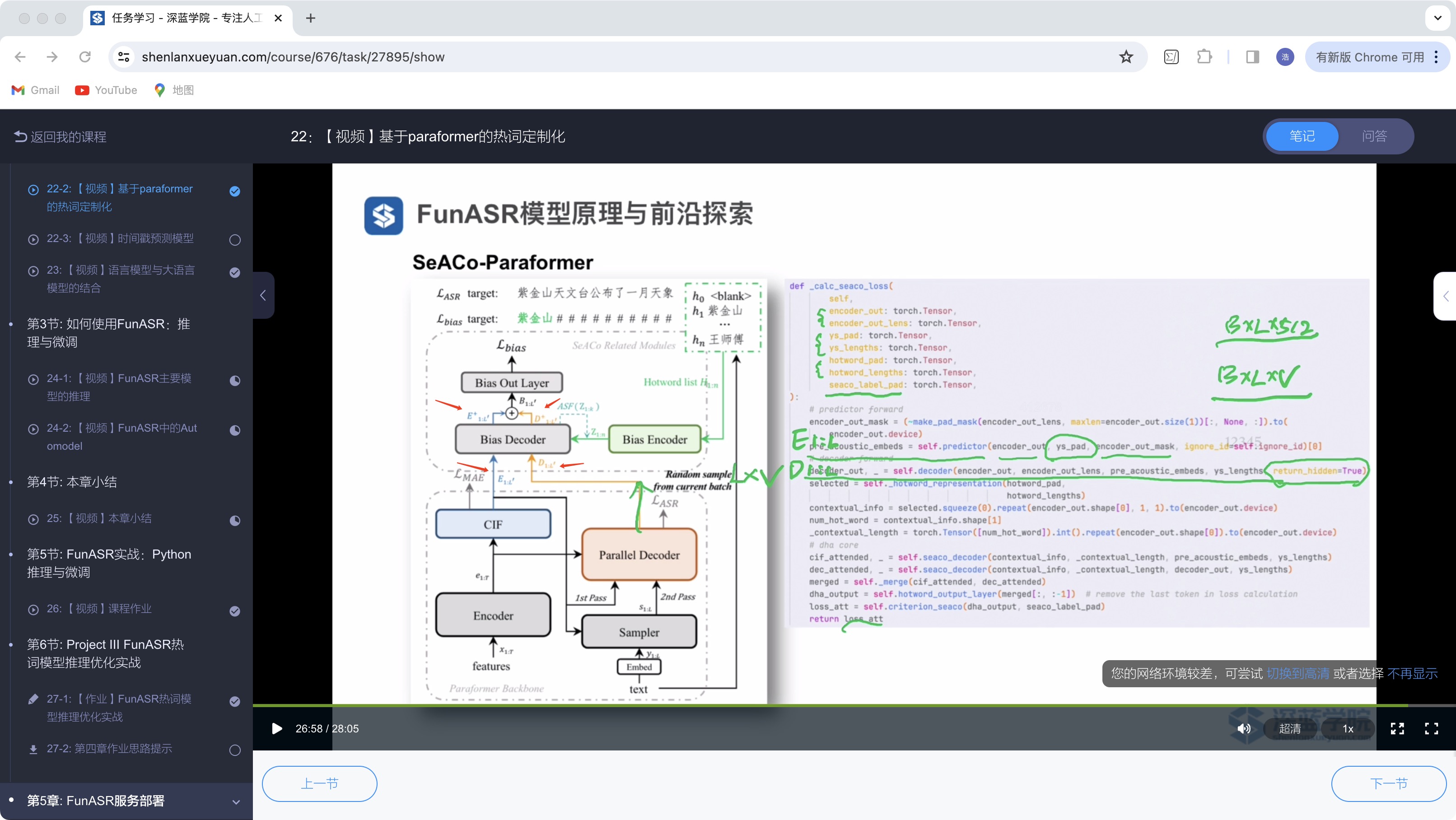
问:这里的E1:L‘ D1:L’ 以及Bias Decoder后E‘1:L‘ D’1:L’ 有点不太理解。他们具体是什么,E1:L‘ 是 B*L‘*512 的维度吗?为啥叫E1:L‘
答:是的,L 代表真实标注的长度,L' 代表CIF 预测的长度,E1:L' 代表CIF 输出,D1:L' 是没有加热词的原Paraformer的输出,E+和D+ 是它们分别用偏置解码器跟热词做注意力计算后的输出
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题3:
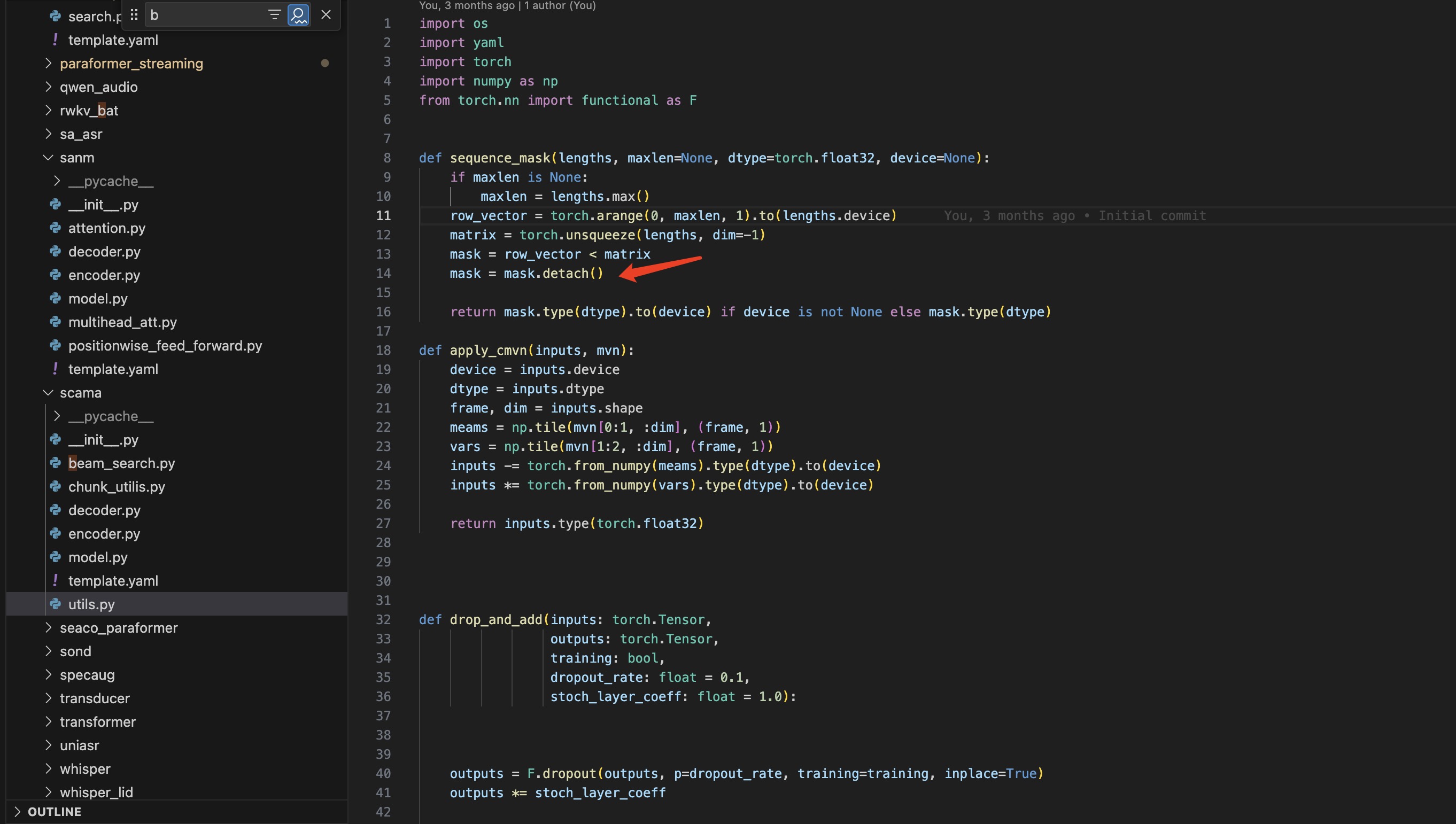
问:这里的mask为啥要加一个detach(),在读ParaformerSANMDecoder的发现的
答:加detach是为了让 mask张量不作为模型可训练参数,可以避免多余的梯度计算
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题4:
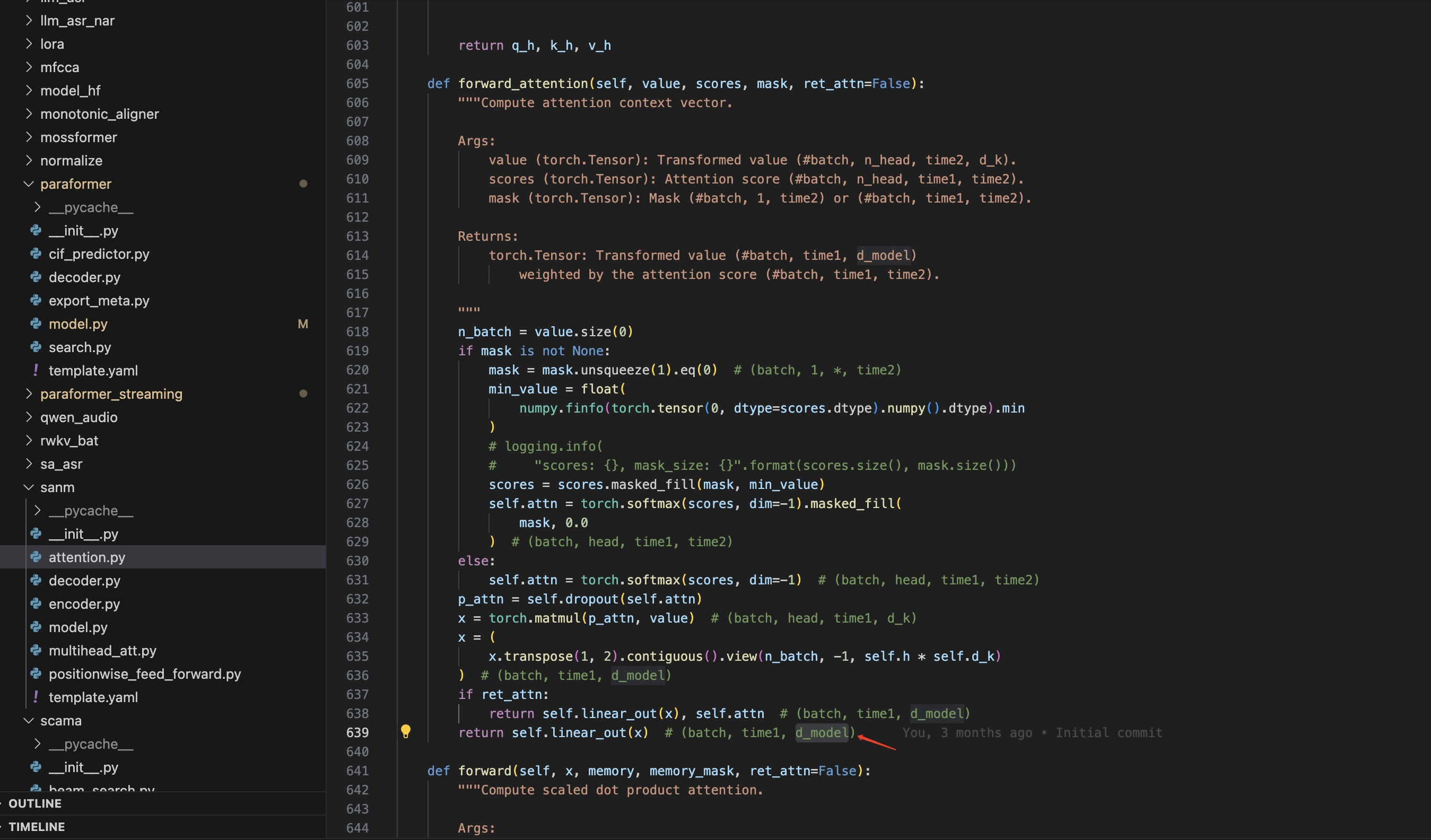
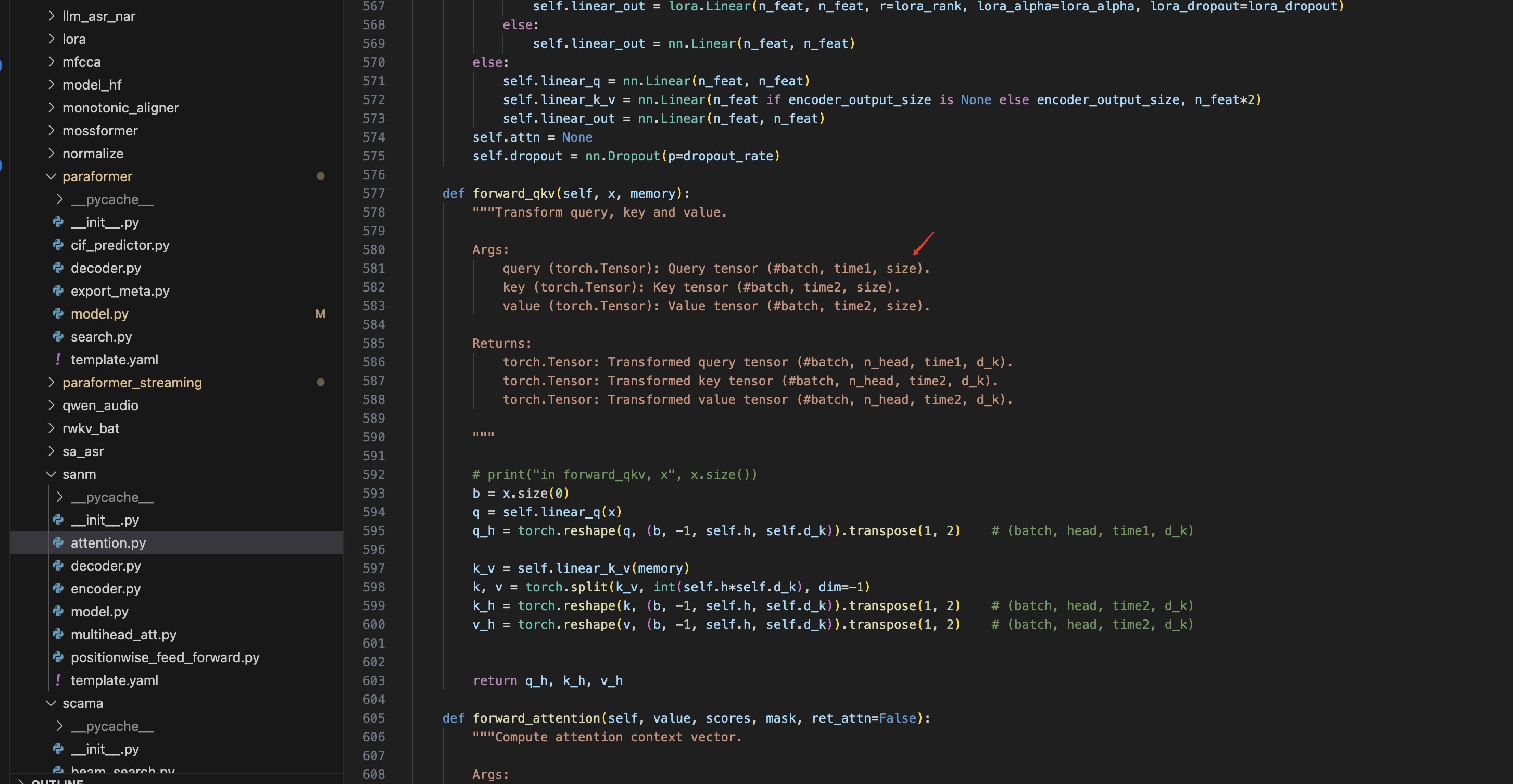
问:这里的d_model和size维度是一样吗,都是512?这个size和d_model的大小有点还不理解,d_model是不是head*dk 最后和size一样。
答:它们分别代表不同的含义,这里的size是输入编码器的语音特征的维度大小,经过linear_q 变换到 d_k 的维度,然后 n_head*d_k 一般设计为等于 d_model 的维度。
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题5:
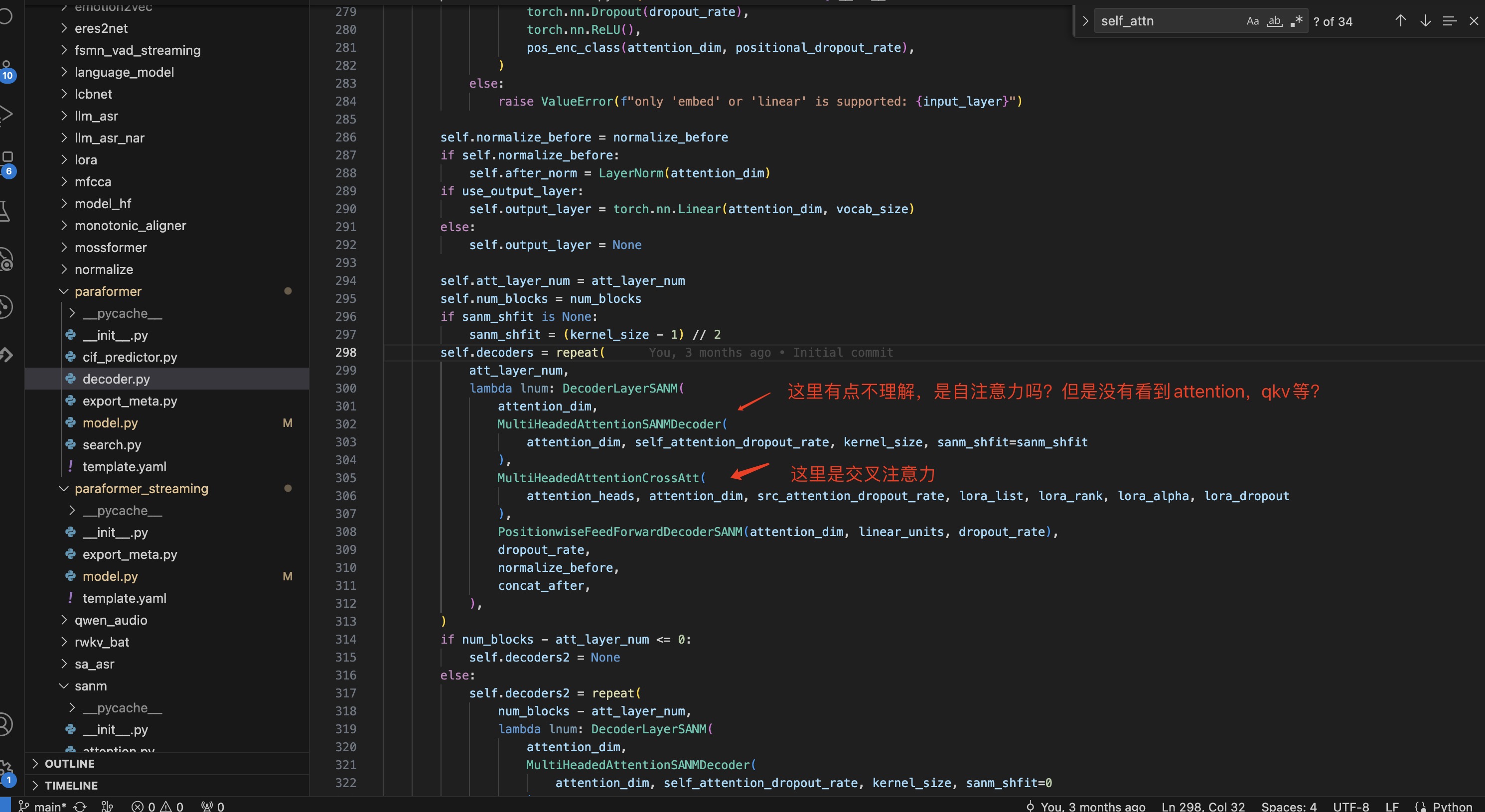
问:对这个MultiHeadedAttentionSANMDecoder网络的作用点不理解,看它forward没有什么注意力的操作。
答:这是个一维卷积,只关注每个位置左右一定范围内的特征,相当于是一种特殊的受限自注意力
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题6:
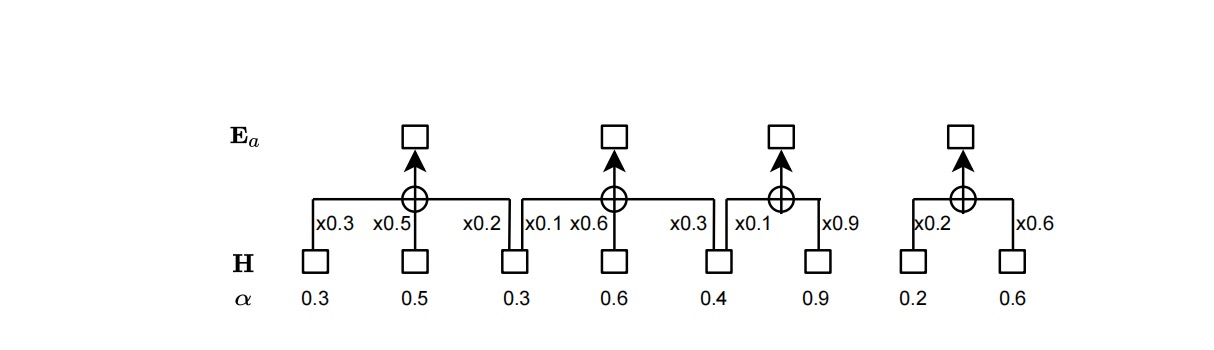
问:Paraformer中这里为什么 CIF 可以根据 aphla 的值重新组合声学特征?
答:我的理解是语音信号中每个词发音结束时会有明显的能量变动,CIF通过积累分数的方式识别出这个变动,来判断每个词的边界。可以参考CIF论文和相关讲解,https://blog.csdn.net/Zwr198/article/details/127938332
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题7:
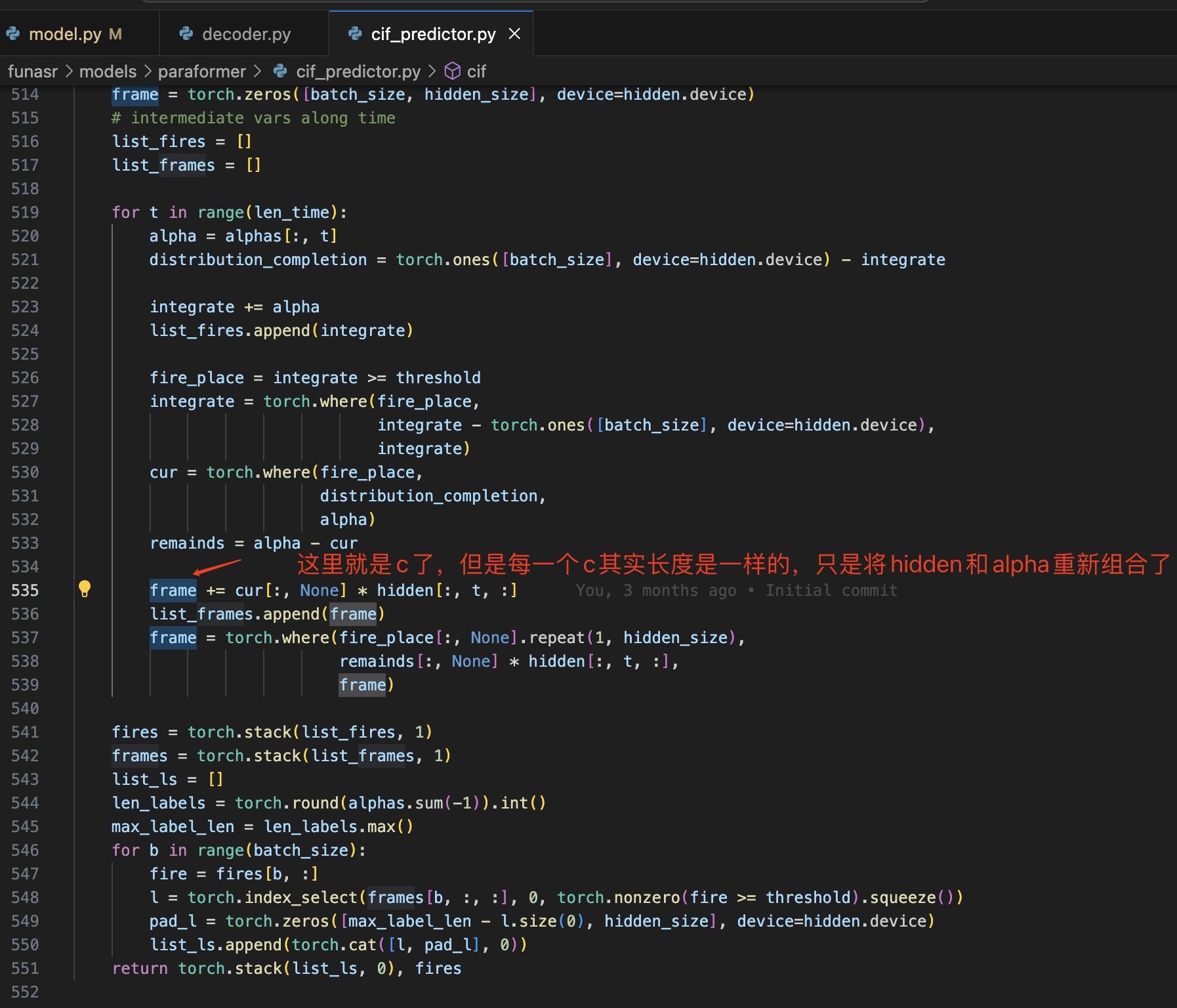
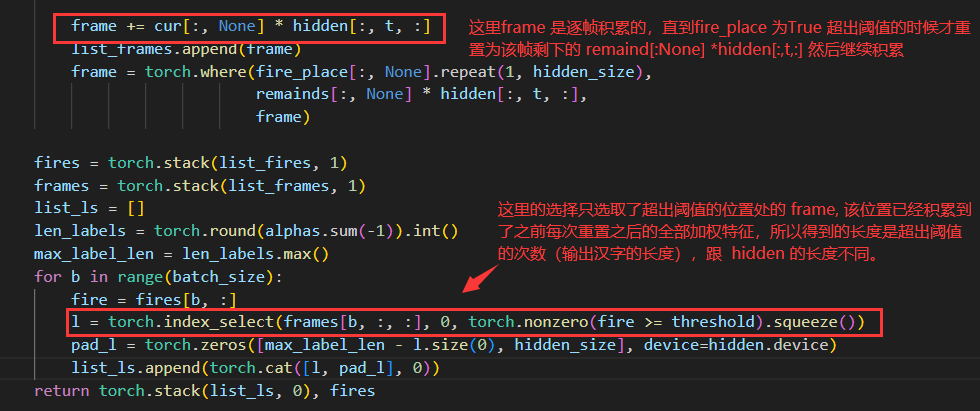
问:我看他cif实际想像HMM一样,用连续不同的帧的来转换成一个汉子,但是我看代码输入和最终生成特征C,其实长度都是一样的。这个是不是有点不对应。
答:代码这里 index_select 部分只选取了达到阈值的累计特征
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题8:
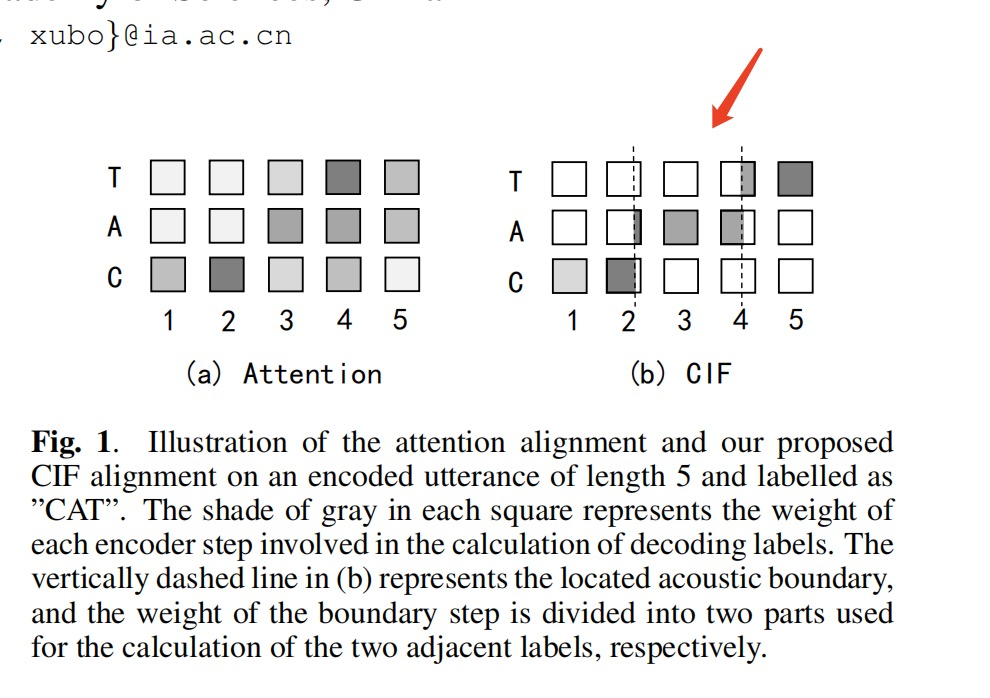

问:根据CIF的论文上的图和算法 , 每个字对应c的特征,c特征的维度都是512,而每个字有发音有长有短。问题一:虽然做了累加但是最终都是512维,每个字发音长短不一,却经过cif后特征都一样长。问题二:做累加的时候,alpha乘以了每个frame的全部,虽然论文的方法是alpha*frame,但是论文开头是只取每个frame的一部分,有点不对应。就这两个地方还有点不理解。从这个图(b)上看只取了一部分,但是method的时候是乘以整个hu.
答: 问题一:CIF 的输出(每个512维的c特征)不再是包含时间长短的全部声学信息,也不是每个字对应的声学特征的压缩表示,而是只代表了对齐相关的信息,例如每个字发音持续的速度时长等,这个信息后面跟编码器输出(全部的声学信息)一起计算注意力解码后才得到每个字的结果。
问题二:method 中 if α<β 这部分对应的是累积的 α 没有阈值时的位置,例如图(b) 中的位置 1 时的计算方式,位置 2 处的累积的 α 超过阈值,编码器特征被分成两部分。CIF 中记录的对齐信息,实现了一种隐藏的筛选机制,只选取声学特征序列中的一段来做注意力计算,而原始的注意力,每个位置都与所有的声学序列特征做注意力计算。在Fig 1 的图(b) 上体现为标注 C 就只对应声学特征位置 1 和 位置2 的前面一部分的声学特征来计算交叉注意力。
问:还有一个困惑的地方,关于问题二:在Fig 1 的图(b) 上体现为标注 C 就只对应声学特征位置 1 和 位置2 的前面一部分的声学特征来。在阅读代码的时候,标注c=位置1*alpha1+位置2*alpha2。 这里的位置2*alpha并不是选取位置2的一部分,而是将其乘以一个权重与前一个做加和,这样是否可以等价呢? 这个有点不大理解。
答: 选取一部分就是把它的 分数alpha2 分成两部分,就是虚线分开两部分的意思,一部分给标注 C,剩下的留给下一个标注 A
-
关于SeaCo Paraformer的问题汇总
——来自《基于端到端的语音识别- 第一期》·17浏览
问题9:
问:第四章有介绍 parallel decoder 结构的内容吗,只听到了 sampler 和 predictor
答:跟transformer 解码器差不多,完整的CIF 输出作为解码器输入跟编码器输出做交叉注意力,不需要自回归就可以并行生成序列结果,可以参考 paraformer/decoder.py 中代码
问:pass2 的话是用 encoder 输出 和 sampler 输出做交叉注意力吗
答:是的,pass2是训练的过程中,根据识别正确率来添加标注嵌入信息到CIF输出中再decoder,推理只需要pass1
-
Transformer代码注释:https://nlp.seas.harvard.edu/annotated-transformer/
-
transformer论文精读:https://mp.weixin.qq.com/s/aRIpZAV93qx1mwJhHzYajQ















