-
策略梯度中参数更新问题
——来自《强化学习理论与实践- 第一期》·32浏览
老师好,策略梯度中的参数更新是按照单步更新的还是回合结束才更新?第一张图中的R()是求一条完整轨迹的回报,所以可以认为是回合更新。但是第二张图的迭代式算法中用了for t=0 to T,每一个小步都计算g(t),也就是从完整的回合中每交互一次进行了一个累加。这前后二者是否矛盾?谢谢老师


-
epsilon-greedy编程
——来自《强化学习理论与实践- 第一期》·20浏览

老师,这是咱们教材中贪婪策略的编程,if后面我看懂了,是以epsilon的概率做任意的动作,但是else后面看不懂他什么意思,难道不是选取使value最大动作的索引值就行了吗?为啥这么复杂,划横线的地方是什么意思没看太懂
-
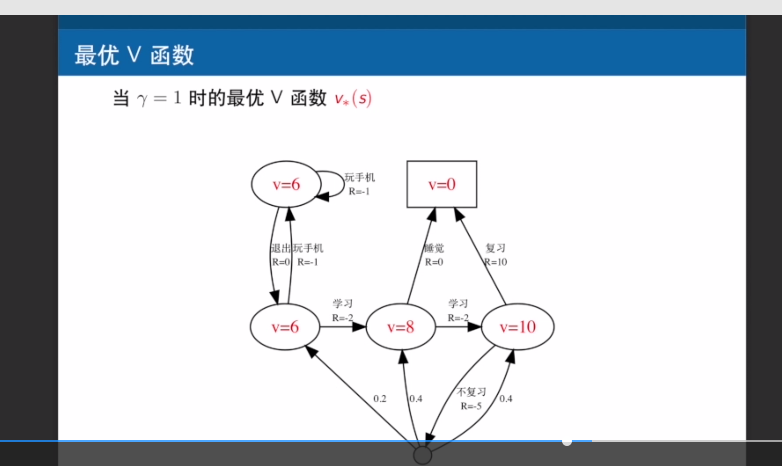
求出各个状态的最优V函数后,如何得出最优策略?
——来自《强化学习理论与实践- 第一期》·28浏览
老师,这幅图在得知了最优V函数后,怎么确定最优策略呢?你在视频里面讲的是把所有episode上的值加一起最大的那个?
-
最优策略指的是什么
——来自《强化学习理论与实践- 第一期》·21浏览
老师你好,这页PPT再讲如何找到一个最优的策略。但之前讲的策略是一个概率分布吧,我们如何找到最优的概率分布呢?
















